
Journal of Systems Engineering and Electronics ›› 2024, Vol. 35 ›› Issue (4): 1042-1052.doi: 10.23919/JSEE.2024.000067
• CONTROL THEORY AND APPLICATION • Previous Articles
Qi WANG( ), Zhizhong LIAO()
), Zhizhong LIAO()
Received:2022-10-31
Online:2024-08-18
Published:2024-08-06
Contact:
Qi WANG
E-mail:wangqibuaa@126.com;lzzcama@139.com
About author:Qi WANG, Zhizhong LIAO. Computational intelligence interception guidance law using online off-policy integral reinforcement learning[J]. Journal of Systems Engineering and Electronics, 2024, 35(4): 1042-1052.
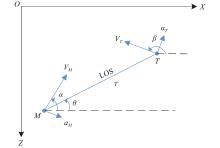
Fig 1
Missile and target engagement geometry"
Table 1
Simulation conditions of Example 1"
| Parameter | Symbol | Value |
| Initial position of missile/m | (0, 0) | |
| Initial FPA of missile/(°) | 0 | |
| Missile velocity/(m·s−1) | 600 | |
| Initial position of target/m | ( | |
| Initial FPA of target/(°) | 210 | |
| Target velocity/(m·s−1) | 200 | |
| Target acceleration/g | 0 | |
| Missile autopilot first-order lag/s | 0.1 | |
| Target autopilot first-order lag/s | 0.1 |
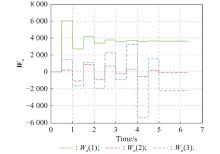
Fig 2
Actor NN weights learned during the online learning guidance stage of Example 1"
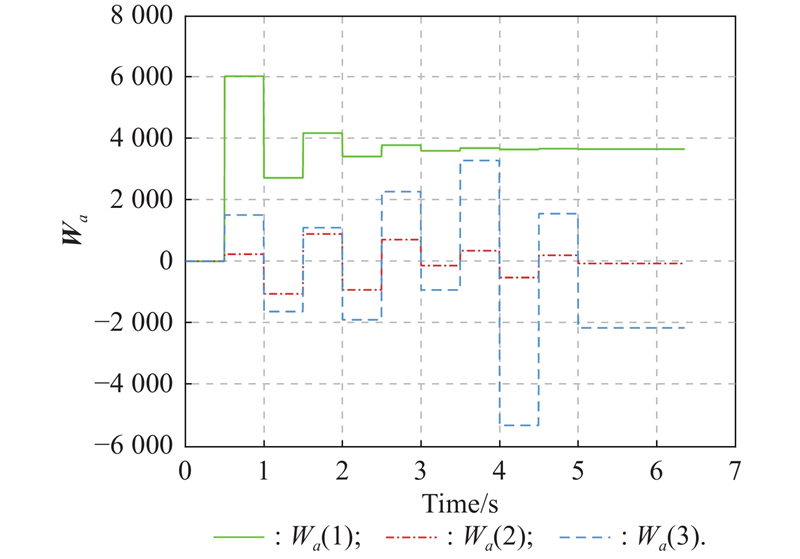
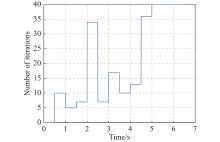
Fig 3
Number of iterations per calculation cycle of Example 1"
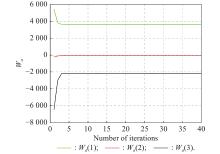
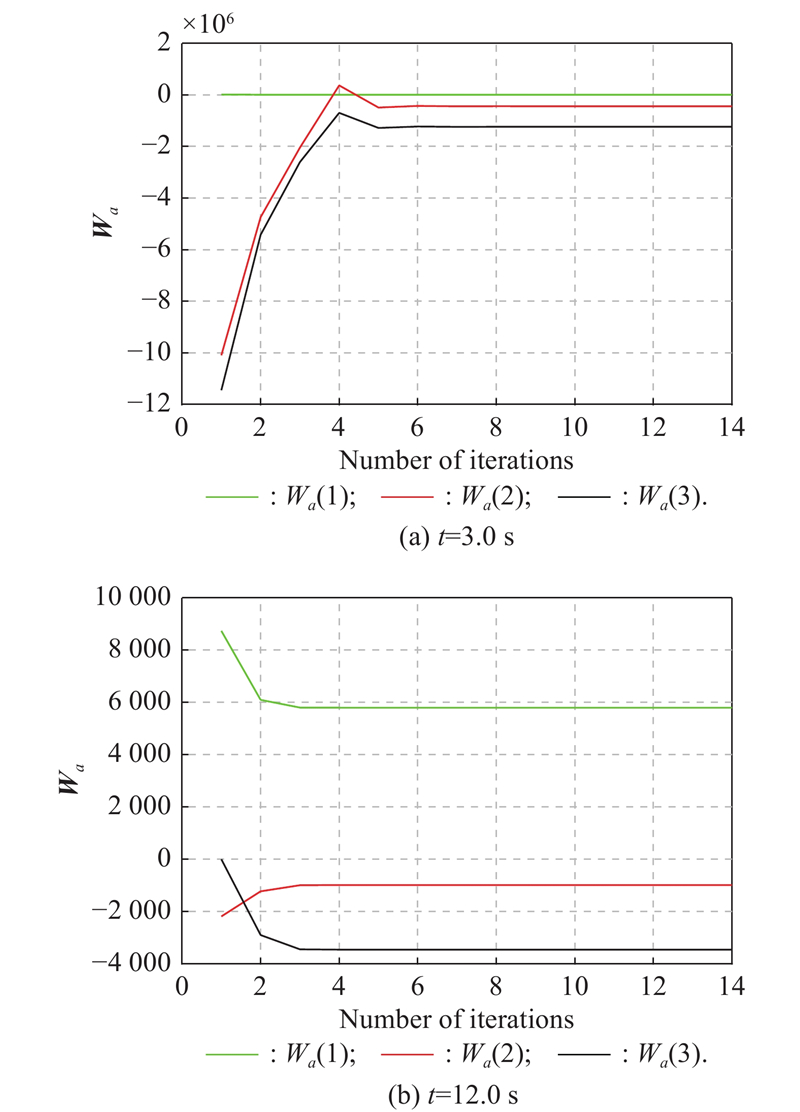
Fig 4
Actor NN weights learning process at t=5.0 s of Example 1"
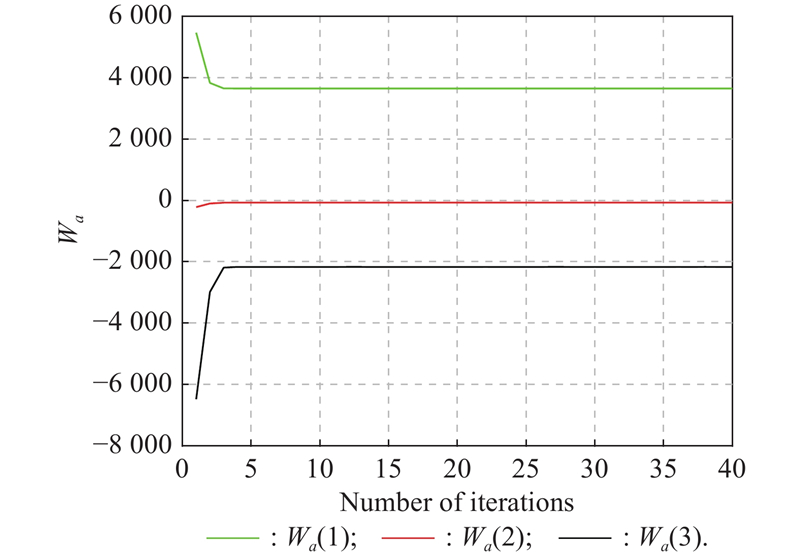
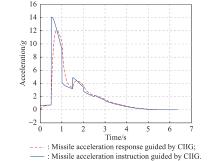
Fig 5
Missile acceleration instruction and response for intercepting non-maneuvering target"
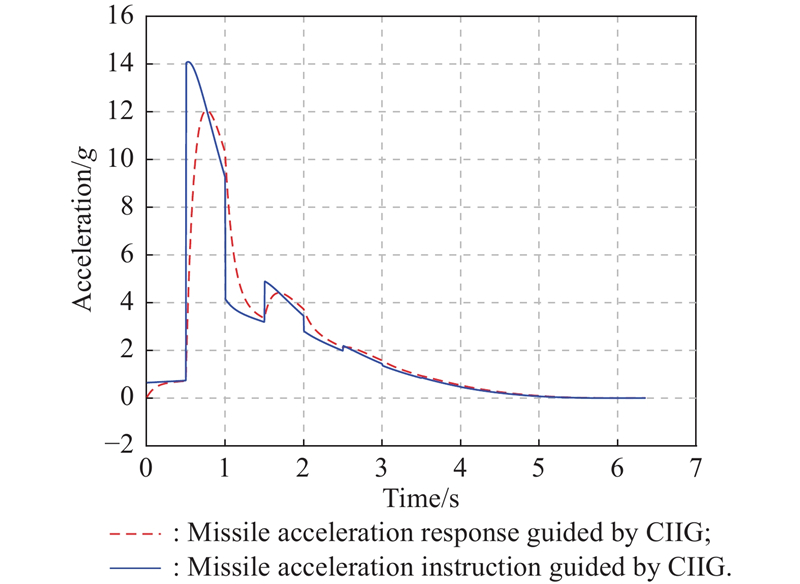
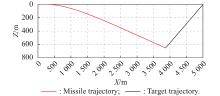
Fig 6
Missile and target trajectories of Example 1"
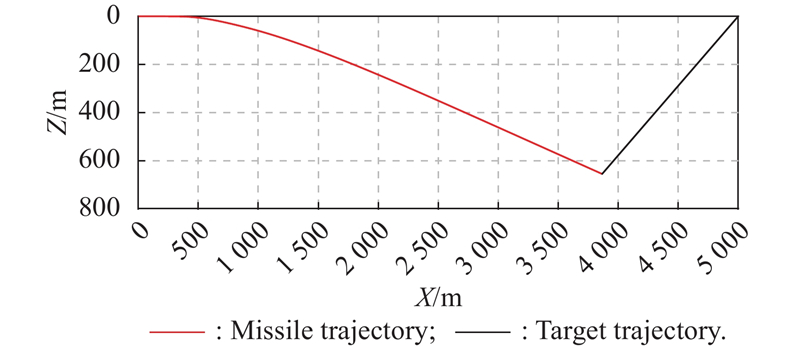
Table 2
Simulation conditions of Example 2"
| Parameter | Symbol | Value |
| Initial position of missile/m | (0, 0) | |
| Initial FPA of missile/(°) | 0 | |
| Missile velocity/(m·s−1) | 600 | |
| Initial position of target/m | ( | |
| Initial FPA of target/(°) | 190 | |
| Target velocity/(m·s−1) | 300 | |
| Target acceleration/g | 12 | |
| Missile autopilot first-order lag/s | 0.1 | |
| Target autopilot first-order lag/s | 0.1 |
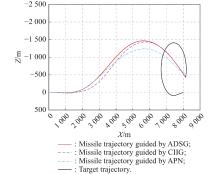
Fig 7
Missile and target trajectories of Example 2"
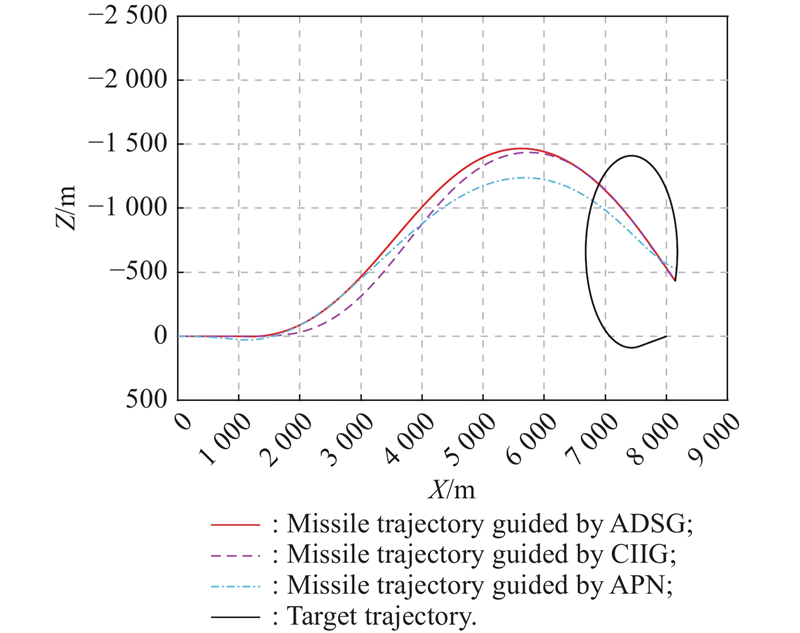
Fig 8
Missile acceleration instruction and response for intercepting high-maneuvering target"
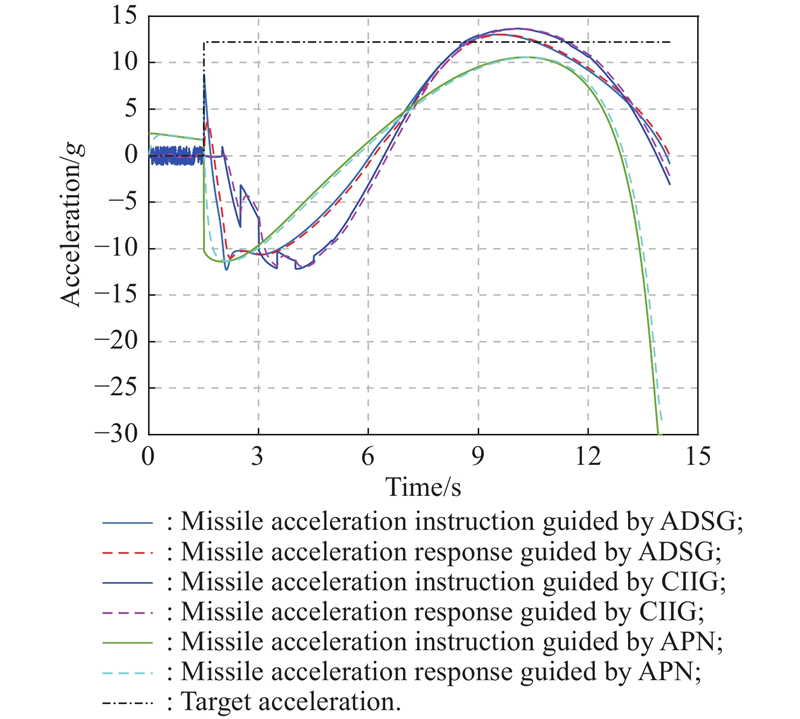
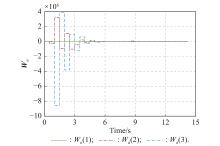
Fig 9
Actor NN weights learned during the online learning guidance stage of Example 2"
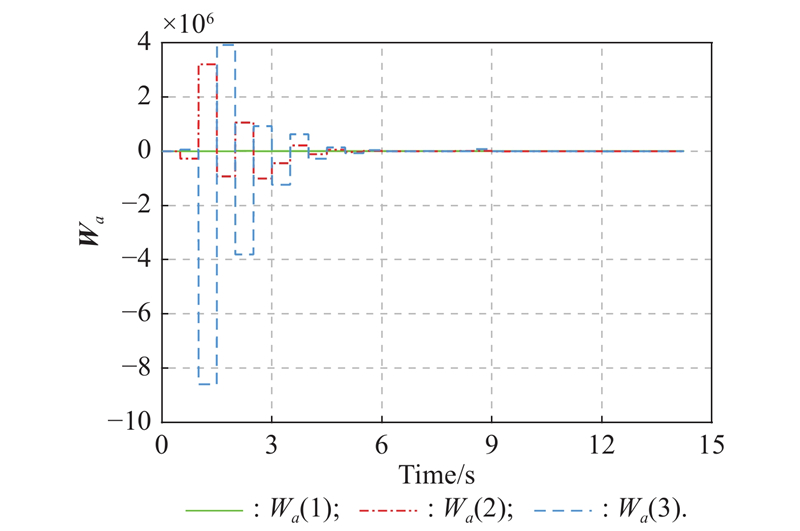
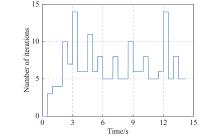
Fig 10
Number of iterations per calculation cycle of Example 2"
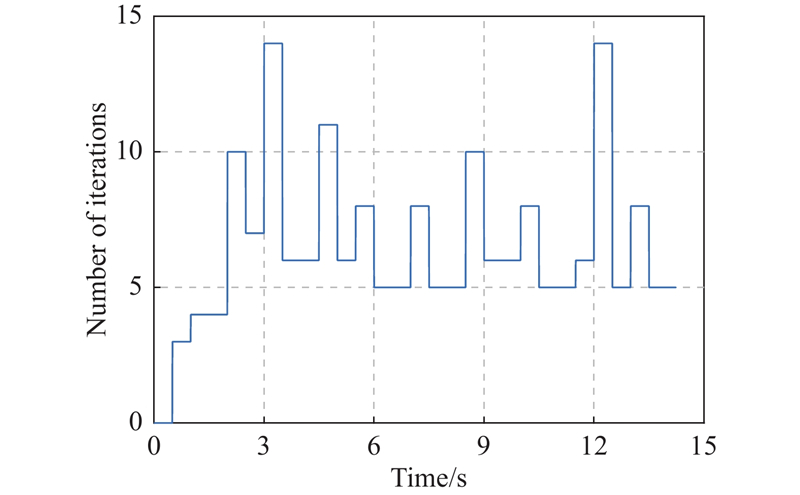
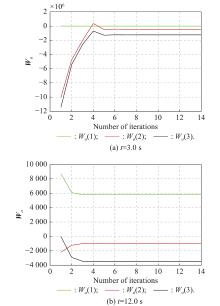
Fig 11
Actor NN weights learning process of Example 2"
| 26 |
YU J L, DONG X W, LI Q D, et al Adaptive practical optimal time-varying formation tracking control for disturbed high-order multi-agent systems. IEEE Trans. on Circuits and Systems, 2022, 69 (6): 2567- 2578.
doi: 10.1109/TCSI.2022.3151464 |
| 27 |
WU H N, LUO B Neural network based online simultaneous policy update algorithm for solving the HJI equation in nonlinear H∞ control. IEEE Trans. on Neural Networks and Learning Systems, 2012, 23 (12): 1884- 1895.
doi: 10.1109/TNNLS.2012.2217349 |
| 28 |
JIANG Y, JIANG Z P Robust adaptive dynamic programming and feedback stabilization of nonlinear systems. IEEE Trans. on Neural Networks and Learning Systems, 2014, 25 (5): 882- 893.
doi: 10.1109/TNNLS.2013.2294968 |
| 29 |
LUO B, WU H N, HUANG T W, et al Data-based approximate policy iteration for affine nonlinear continuous-time optimal control design. Automatica, 2014, 50 (12): 3281- 3290.
doi: 10.1016/j.automatica.2014.10.056 |
| 30 |
LUO B, WU H N, HUANG T W Off-policy reinforcement learning for H∞ control design. IEEE Trans. on Cybernetics, 2015, 45 (1): 65- 76.
doi: 10.1109/TCYB.2014.2319577 |
| 31 |
FU Y, CHAI T Y Online solution of two-player zero-sum games for continuous-time nonlinear systems with completely unknown dynamics. IEEE Trans. on Neural Networks and Learning Systems, 2016, 27 (12): 2577- 2587.
doi: 10.1109/TNNLS.2015.2496299 |
| 32 | BASAR T, BERNHARD P. H∞ optimal control and related minimax design problems. Massachusetts: Springer Science, 1995. |
| 33 |
VAN D S A J L2-gain analysis of nonlinear systems and nonlinear state-feedback H∞ control. IEEE Trans. on Automatic Control, 1992, 37 (6): 770- 784.
doi: 10.1109/9.256331 |
| 34 |
ABU-KHALAF M, LEWIS F L, HUANG J Neurodynamic programming and zero-sum games for constrained control systems. IEEE Trans. on Neural Networks, 2008, 19 (7): 1243- 1252.
doi: 10.1109/TNN.2008.2000204 |
| 35 |
VRABIE D, LEWIS F Neural network approach to continuous-time direct adaptive optimal control for partially unknown nonlinear systems. Neural Networks, 2009, 22 (3): 237- 246.
doi: 10.1016/j.neunet.2009.03.008 |
| 36 |
HORNIK K, STINCHCOMBE M, WHITE H Universal approximation of an unknown mapping and its derivatives using multilayer feedforward networks. Neural Networks, 1990, 3 (5): 551- 560.
doi: 10.1016/0893-6080(90)90005-6 |
| 37 |
MODARES H, FRANK L, JIANG Z P H∞ tracking control of completely unknown continuous-time systems via off-policy reinforcement learning. IEEE Trans. on Neural Networks and Learning Systems, 2015, 26 (10): 2550- 2562.
doi: 10.1109/TNNLS.2015.2441749 |
| 38 |
BARDHAN R, GHOSE D Nonlinear differential games-based impact-angle-constrained guidance law. Journal of Guidance, Control, and Dynamics, 2015, 38 (3): 384- 402.
doi: 10.2514/1.G000940 |
| 1 |
YANG C D, YANG C C Analytical solution of three-dimensional realistic true proportional navigation. Journal of Guidance Control and Dynamics, 1996, 19 (3): 569- 577.
doi: 10.2514/3.21659 |
| 2 | PALUMBO N F, BLAUWKAMP R A, LLOYD J M Modern homing missile guidance theory and techniques. Johns Hopkins APL Technical Digest, 2010, 29 (1): 42- 59. |
| 3 |
ZHOU D, MU C D, XU W L Adaptive sliding-mode guidance of a homing missile. Journal of Guidance, Control, and Dynamics, 1999, 22 (4): 589- 594.
doi: 10.2514/2.4421 |
| 4 |
WANG X X, HUANG X L, DING S C Terminal angle constraint finite-time guidance law with input saturation and autopilot dynamics. Journal of the Franklin Institute, 2022, 359 (16): 8687- 8712.
doi: 10.1016/j.jfranklin.2022.08.046 |
| 5 | ZHOU D, XU B Adaptive dynamic surface guidance law with input saturation constraint and autopilot dynamics. Journal of Guidance, Control, and Dynamics, 2016, 39 (5): 1152- 1159. |
| 6 | WANG Q, LIAO Z Z. Implementation method of parallel approaching guidance based on adaptive dynamic surface control accounting for autopilot lag. Proc. of the International Conference on Guidance, Navigation and Control, 2022: 309–317. |
| 7 | DWIVEDI P N, BHATTACHARYYA A, PADHI R. Computationally efficient suboptimal mid course guidance using model predictive static programming. Proc. of the 17th World Congress, 2008: 3550–3555. |
| 8 |
DWIVEDI P N, BHATTACHARYA A, PADHI R Suboptimal midcourse guidance of interceptors for high-speed targets with alignment angle constraint. Journal of Guidance, Control, and Dynamics, 2011, 34 (3): 860- 877.
doi: 10.2514/1.50821 |
| 9 |
HALBE O, RAJA R G, PADHI R Robust reentry guidance of a reusable launch vehicle using model predictive static programming. Journal of Guidance, Control, and Dynamics, 2014, 37 (1): 134- 148.
doi: 10.2514/1.61615 |
| 10 |
OZA H B, PADHI R Impact-angle-constrained suboptimal model predictive static programming guidance of air-to-ground missiles. Journal of Guidance, Control, and Dynamics, 2012, 35 (1): 153- 164.
doi: 10.2514/1.53647 |
| 11 |
TRIPATHI A K, PADHI R Autonomous landing for UAVs using T-MPSP guidance and dynamic inversion autopilot. IFAC Papers-OnLine, 2016, 49 (1): 18- 23.
doi: 10.1016/j.ifacol.2016.03.022 |
| 12 |
PAN B F, MA Y Y, YAN R Newton-type methods in computational guidance. Journal of Guidance, Control, and Dynamics, 2019, 42 (2): 377- 383.
doi: 10.2514/1.G003931 |
| 13 |
PING L Introducing computational guidance and control. Journal of Guidance, Control, and Dynamics, 2017, 40 (2): 193.
doi: 10.2514/1.G002745 |
| 14 | TSIOTRAS P, MESBAHI M Toward an algorithmic control theory. Journal of Guidance, Control, and Dynamics, 2017, 40 (2): 194- 196. |
| 15 | HOWARD R A. Dynamic programming and Markov processes. Massachusetts: MIT Press, 1960. |
| 16 |
WEI Q L, WANG F Y, LIU D R, et al Finite-approximation-error-based discrete-time iterative adaptive dynamic programming. IEEE Trans. on Cybernetics, 2014, 44 (12): 2820- 2833.
doi: 10.1109/TCYB.2014.2354377 |
| 17 |
LEWIS F L, VRABIE D Reinforcement learning and adaptive dynamic programming for feedback control. IEEE Circuits and Systems Magazine, 2009, 9 (3): 32- 50.
doi: 10.1109/MCAS.2009.933854 |
| 18 | GAUDET B, FURFARO R. Missile homing-phase guidance law design using reinforcement learning. Proc. of the AIAA Guidance, Navigation, and Control Conference, 2012. DOI: 10.2514/6.2012-4470. |
| 19 | GAUDET B, FURFARO R, LINARES R Reinforcement learning for angle-only intercept guidance of maneuvering targets. Aerospace Science and Technology, 2020, 99, 105746. |
| 20 |
HE S, SHIN H S, TSOURDOS A Computational missile guidance: a deep reinforcement learning approach. Journal of Aerospace Information Systems, 2021, 18 (8): 571- 582.
doi: 10.2514/1.I010970 |
| 21 |
LI W F, ZHU Y H, ZHAO D B Missile guidance with assisted deep reinforcement learning for head-on interception of maneuvering target. Complex & Intelligent Systems, 2021, 8 (3): 1205- 1216.
doi: 10.1007/s40747-021-00577-6 |
| 22 | WANG Q, LIAO Z Z, YAN F. Computational guidance law based on data-driven online adaptive critic designs. Proc. of the China Automation Congress, 2021: 1289−1294. |
| 23 |
SUN J L, LIU C S Backstepping-based adaptive dynamic programming for missile-target guidance systems with state and input constraints. Journal of the Franklin Institute, 2018, 355 (17): 8412- 8440.
doi: 10.1016/j.jfranklin.2018.08.024 |
| 24 | WANG Q, LIAO Z Z Computational intelligence game guidance law based on online adaptive dynamic programming. Aerospace Control, 2022, 40 (6): 48- 54. |
| 25 |
YU J L, DONG X W, LI Q D, et al Task coupling based layered cooperative guidance: theories and applications. Control Engineering Practice, 2022, 121, 105050.
doi: 10.1016/j.conengprac.2021.105050 |
| No related articles found! |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||