
Journal of Systems Engineering and Electronics ›› 2023, Vol. 34 ›› Issue (1): 9-18.doi: 10.23919/JSEE.2023.000035
• REMOTE SENSING • Previous Articles Next Articles
Tingting WEI( ), Weilin YUAN(), Junren LUO(), Wanpeng ZHANG(), Lina LU()
), Weilin YUAN(), Junren LUO(), Wanpeng ZHANG(), Lina LU()
Received:2022-08-30
Accepted:2023-01-13
Online:2023-02-18
Published:2023-03-03
Contact:
Wanpeng ZHANG
E-mail:weitingting20@nudt.edu.cn;yuanweilin12@nudt.edu.cn;luojunren17@nudt.edu.cn;wpzhang@nudt.edu.cn;lulina16@nudt.edu.cn
About author:Supported by:Tingting WEI, Weilin YUAN, Junren LUO, Wanpeng ZHANG, Lina LU. VLCA: vision-language aligning model with cross-modal attention for bilingual remote sensing image captioning[J]. Journal of Systems Engineering and Electronics, 2023, 34(1): 9-18.
Add to citation manager EndNote|Reference Manager|ProCite|BibTeX|RefWorks
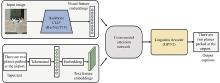
Fig 1
Framework of the VLCA for bilingual RSIC"
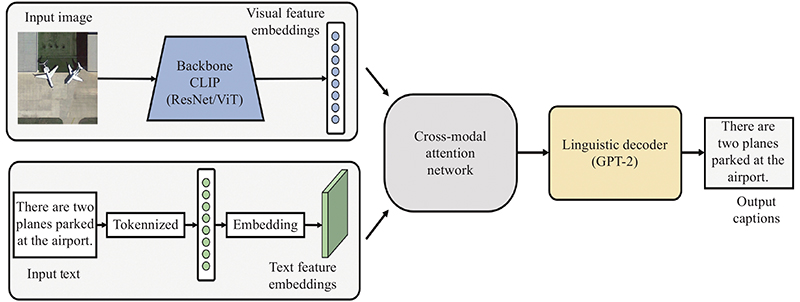
Fig 2
Structure of the CMN"
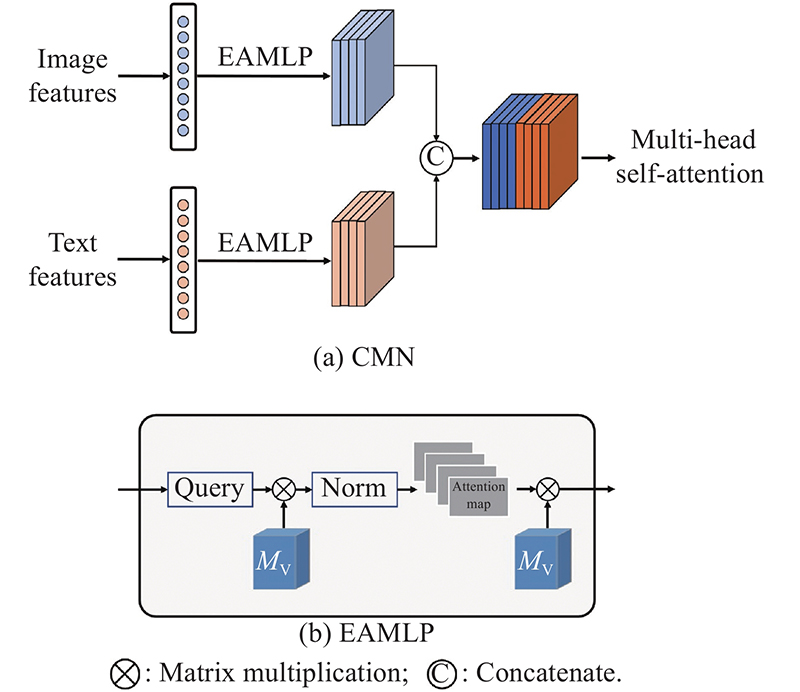
Table 1
Comparison of different datasets"
| Dataset | Category number | Average caption length | Vocabulary size | Number of images |
| Sydney [ | 21 | 11.5 | 315 | 2,100 |
| University of California Merced [ | 7 | 13.2 | 231 | 613 |
| RSICD [ | 30 | 11.4 | 2695 | 10 000 |
| DIOR-Captions | 20 | 11.2 | 376 | 16 565 |

Fig 3
Examples of DIOR-Captions"

Table 2
Details of the training process"
| Parameter | Value |
| Initial learning rate | |
| Batch size | 40 |
| Epoch | 50 |
| Warmup step | 4000 |
| Number of external attention heads | 8 |
| Word embedding dimension | 512 |
| Model dimensionality of GPT-2 | 768 |
| CLIP embedding dimension | 512 |
| Probability value of TopP | 0.9 |
| Max captions length | 20 |
Table 3
Metric results of different method"
| Method | BLEU4 | ROUGE-L | METEOR | CIDEr |
| VMM [ | 0.293 | 0.660 | 0.286 | 1.292 |
| SOA [ | 0.294 | 0.631 | 0.279 | 1.469 |
| FCA [ | 0.355 | 0.655 | 0.308 | 2.149 |
| SMA [ | 0.342 | 0.659 | 0.307 | 2.033 |
| SCA [ | 0.369 | 0.685 | 0.317 | 2.200 |
| VLCA-ViT | 0.309 | 0.631 | 0.372 | 2.293 |
| VLCA-ResNet | 0.401 | 0.696 | 0.330 | 2.591 |
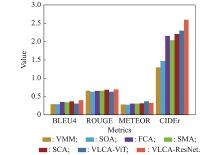
Fig 4
Comparison of different methods"
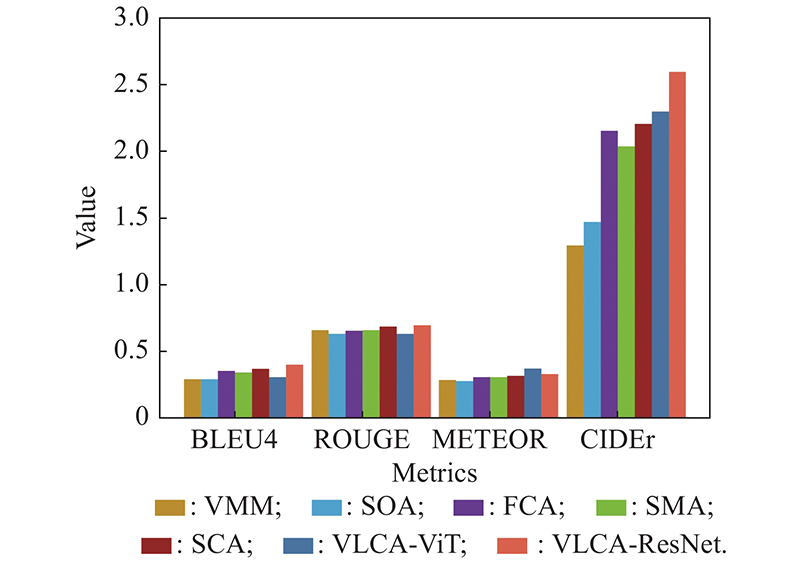

Fig 5
English captions results of VLCA compared with VMM and SCA"

Fig 6
Comparison of each metric for ablation experiments"
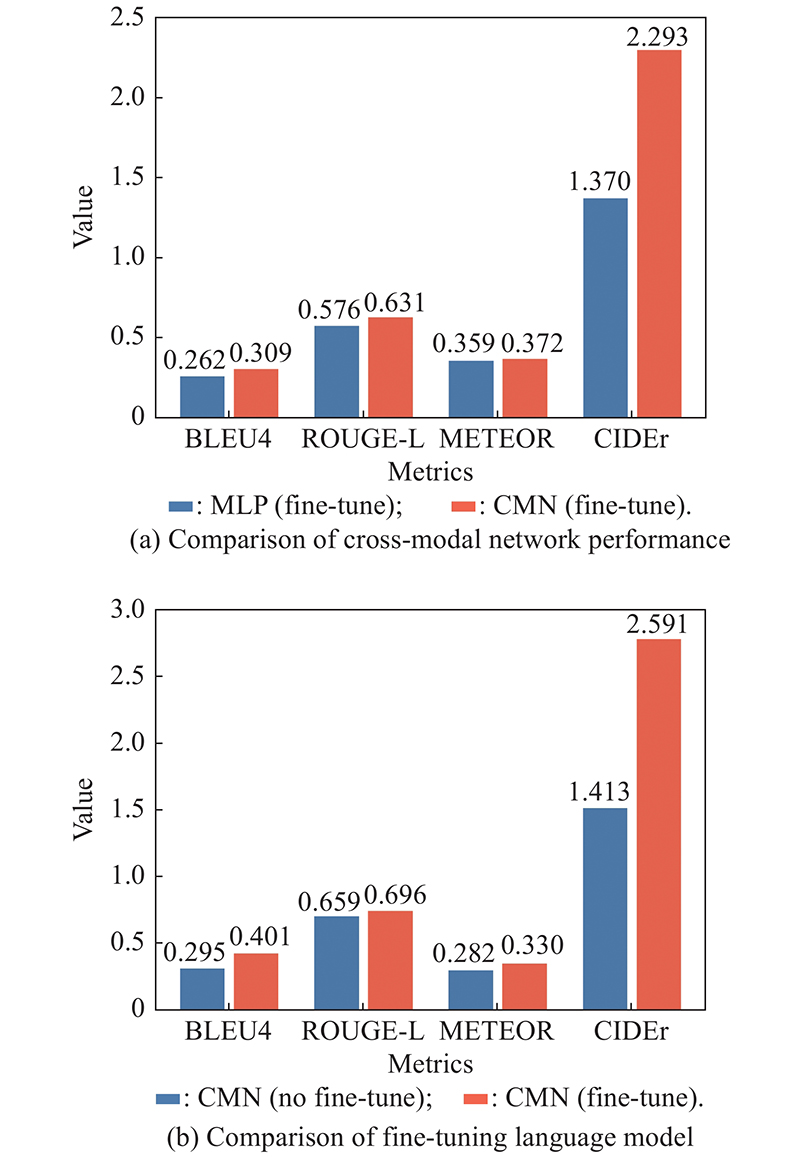
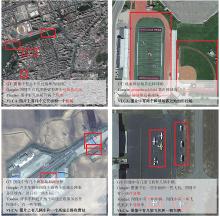
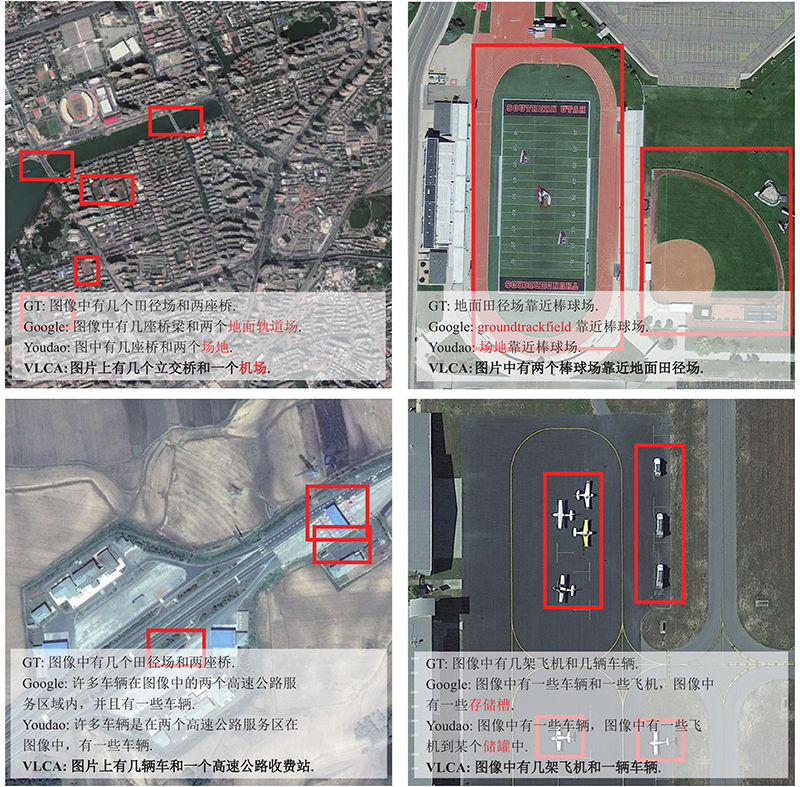
Fig 7
Chinese captions results of VLCA compared with Google and Youdao translate"
| 1 |
GAO L N, BI F K, YANG J Visual attention based model for target detection in large-field images. Journal of Systems Engineering and Electronics, 2011, 22 (1): 150- 156.
doi: 10.3969/j.issn.1004-4132.2011.01.020 |
| 2 |
MOGADALA A, KALIMUTHU M, KLAKOW D Trends in integration of vision and language research: a survey of tasks, datasets, and methods. Journal of Artificial Intelligence Research, 2021, 71, 1183- 1317.
doi: 10.1613/jair.1.11688 |
| 3 | QU B, LI X L, TAO D C, et al. Deep semantic understanding of high resolution remote sensing image. Proc. of the IEEE International conference on Computer, Information and Telecommunication Systems, 2016. DOI: 10.1109/CITS.2016.7546397. |
| 4 | YUAN Z Q, ZHANG W K, TIAN C Y, et al Remote sensing cross-modal text-image retrieval based on global and local information. IEEE Trans. on Geoscience and Remote Sensing, 2022, 60, 5620616. |
| 5 |
SHI Z W, ZOU Z X Can a machine generate humanlike language descriptions for a remote sensing image? IEEE Trans. on Geoscience and Remote Sensing, 2017, 55 (6): 3623- 3634.
doi: 10.1109/TGRS.2017.2677464 |
| 6 | LU X Q, WANG B Q, ZHENG X T, et al Exploring models and data for remote sensing image caption generation. IEEE Trans. on Geoscience and Remote Sensing, 2017, 56 (4): 2183- 2195. |
| 7 |
WANG B Q, LU X Q, ZHENG X T, et al Semantic descriptions of high-resolution remote sensing images. IEEE Geoscience and Remote Sensing Letters, 2019, 16 (8): 1274- 1278.
doi: 10.1109/LGRS.2019.2893772 |
| 8 | LU X Q, WANG B Q, ZHENG X T Sound active attention framework for remote sensing image captioning. IEEE Trans. on Geoscience and Remote Sensing, 2019, 58 (3): 1985- 2000. |
| 9 | ZHAO R, SHI Z W, ZOU Z X High-resolution remote sensing image captioning based on structured attention. IEEE Trans. on Geoscience and Remote Sensing, 2021, 60, 5603814. |
| 10 | RADFORD A, KIM J W, HALLACY C, et al Learning transferable visual models from natural language supervision. Proc. of the International Conference on Machine Learning, 2021, 8748- 8763. |
| 11 | SHEN S, LI L H, TAN H, et al. How much can CLIP benefit vision-and-language tasks? http://arxiv.org/abs/2107.06383. |
| 12 | LU J S, GOSWAMI V, ROHRBACH M, et al. 12-in-1: multi-task vision and language representation learning. Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 10437−10446. |
| 13 | MOKADY R, HERTZ A, BERMANO A H. Clipcap: clip prefix for image captioning. https://arxiv.org/abs/2111.09734. |
| 14 | DU Y F, LIU Z K, LI J Y, et al. A survey of vision-language pre-trained models. https://arxiv.org/abs/2202.10936. |
| 15 | ZHOU L W, PALANGI H, ZHANG L, et al. Unified vision-language pre-training for image captioning and VQA. Proc. of the AAAI Conference on Artificial Intelligence, 2020, 34: 13041−13049. |
| 16 |
LI K, WAN G, CHENG G, et al Object detection in optical remote sensing images: a survey and a new benchmark. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 159, 296- 307.
doi: 10.1016/j.isprsjprs.2019.11.023 |
| 17 |
ZHANG X R, WANG X, TANG X, et al Description generation for remote sensing images using attribute attention mechanism. Remote Sensing, 2019, 11 (6): 612.
doi: 10.3390/rs11060612 |
| 18 | WU S Q, ZHANG X R, WANG X, et al. Scene attention mechanism for remote sensing image caption generation. Proc. of IEEE the International Joint Conference on Neural Networks, 2020. DOI: 10.1109/IJCNN48605.2020.9207381. |
| 19 | LI X J, YIN X, LI C Y, et al Oscar: object-semantics aligned pre-training for vision-language tasks. Proc. of the European Conference on Computer Vision, 2020, 121- 137. |
| 20 | LU J S, BATRA D, PARIKH D, et al. Vilbert: pretraining task-agnostic vision linguistic representations for vision-and-language tasks. Advances in Neural Information Processing Systems, 2019. DOI: 10.48550/arXiv.1908.02265. |
| 21 | MIYAZAKI T, SHIMIZU N. Cross-lingual image caption generation. Proc. of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2016: 1780−1790. |
| 22 |
LI X R, XU C X, WANG X X, et al COCO-CN for cross-lingual image tagging, captioning, and retrieval. IEEE Trans. on Multimedia, 2019, 21 (9): 2347- 2360.
doi: 10.1109/TMM.2019.2896494 |
| 23 |
WANG B, WANG C G, ZHANG Q, et al Cross-lingual image caption generation based on visual attention model. IEEE Access, 2020, 8, 104543- 104554.
doi: 10.1109/ACCESS.2020.2999568 |
| 24 | RADFORD A, WU J, CHILD R, et al Language models are unsupervised multitask learners. OpenAI Blog, 2019, 1 (8): 9. |
| 25 | DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: transformers for image recognition at scale. https://arxiv.org/abs/2010.11929. |
| 26 | HE K M, ZHANG X, REN S Q, et al Deep residual learning for image recognition. Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, 770- 778. |
| 27 | VASWANI A, SHAZEER N, PARMAR N, et al Attention is all you need. Advances in Neural Information Processing Systems, 2017, 6000- 6010. |
| 28 | GUO M H, LIU Z N, MU T J, et al. Beyond self-attention: external attention using two linear layers for visual tasks. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2022. DOI: 10.1109/TPAMI.2022.3211006. |
| 29 |
GUO M H, CAI J X, LIU Z N, et al Pct: point cloud transformer. Computational Visual Media, 2021, 7 (2): 187- 199.
doi: 10.1007/s41095-021-0229-5 |
| 30 | HOLTZMAN A, BUYS J, DU L, et al. The curious case of neural text degeneration. https://arxiv.org/abs/1904.09751. |
| 31 | DIEDERIK P K, BA J. Adam: a method for stochastic optimization. http://arxiv.org/abs.1412.6980. |
| 32 | LUO R T. Image captioning. https://github.com/ruotianluo/ImageCaptioning.pytorch. |
| 33 | PAPINENI K, ROUKOS S, WARD T, et al. Bleu: a method for automatic evaluation of machine translation. Proc. of the 40th Annual Meeting of the Association for Computational Linguistics, 2002: 311−318. |
| 34 | LIN C Y. 2004. ROUGE: a package for automatic evaluation of summaries. Proc. of the ACL-04 Workshop, 2004: 74–81. |
| 35 | DENKOWSKI M, LAVIE A. Meteor universal: language specific translation evaluation for any target language. Proc. of the Ninth Workshop on Statistical Machine Translation, 2014: 376−380. |
| 36 | VEDANTAM R, LAWRENCE ZITNICK C, et al Cider: consensus-based image description evaluation. Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, 4566- 4575. |
| 37 | HANNUN A Y, MAAS A L, JURAFSKY D, et al. First-pass large vocabulary continuous speech recognition using bi-directional recurrent DNNs. https://arxiv.org/abs/1408.2873. |
| 38 | SUN J Y. Jieba. https://github.com/fxsjy/jieba. |
| 39 | DU Z Y. GPT2-Chinese. https://github.com/Morizeyao/GPT2-Chinese. |
| No related articles found! |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||