
Journal of Systems Engineering and Electronics ›› 2021, Vol. 32 ›› Issue (6): 1490-1508.doi: 10.23919/JSEE.2021.000126
• CONTROL THEORY AND APPLICATION • Previous Articles Next Articles
Kaifang WAN*( ), Bo LI(), Xiaoguang GAO(), Zijian HU(), Zhipeng YANG()
), Bo LI(), Xiaoguang GAO(), Zijian HU(), Zhipeng YANG()
Received:2020-12-02
Accepted:2021-11-09
Online:2022-01-05
Published:2022-01-05
Contact:
Kaifang WAN
E-mail:wankaifang@nwpu.edu.cn;Libo803@nwpu.edu.cn;cxg2012@nwpu.edu.cn;huzijian@mail.nwpu.edu.cn;yzp@mail.nwpu.edu.cn
About author:Supported by:Kaifang WAN, Bo LI, Xiaoguang GAO, Zijian HU, Zhipeng YANG. A learning-based flexible autonomous motion control method for UAV in dynamic unknown environments[J]. Journal of Systems Engineering and Electronics, 2021, 32(6): 1490-1508.
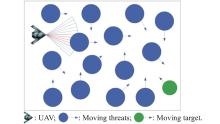
Fig 1
Top view of the AMC scenario"
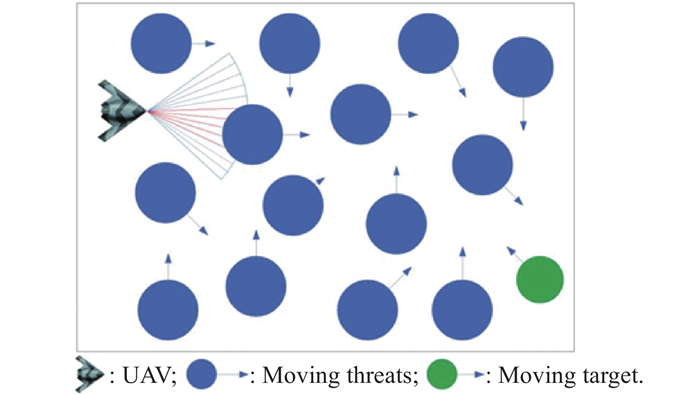
Fig 2
DRL-based motion-control structure of the UAV"
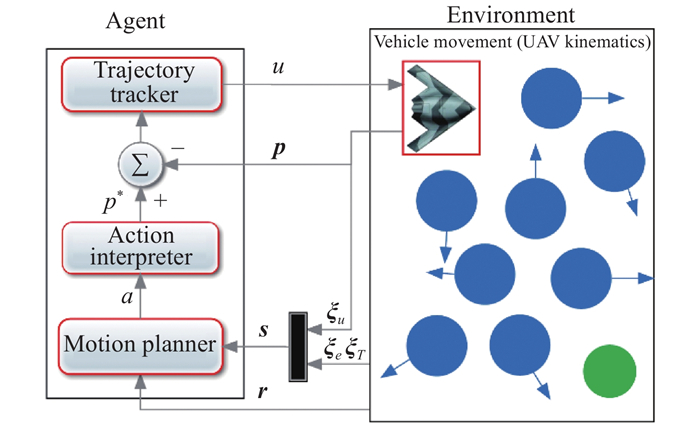

Fig 3
Mathematical definitions of the UAV"
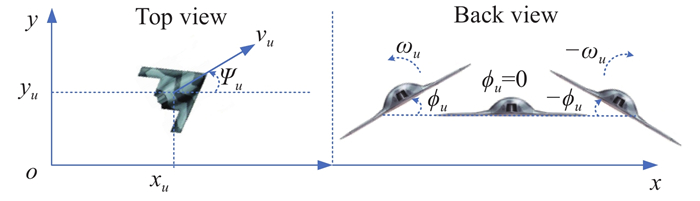
Fig 4
Diagram of UAV sequential decision process"
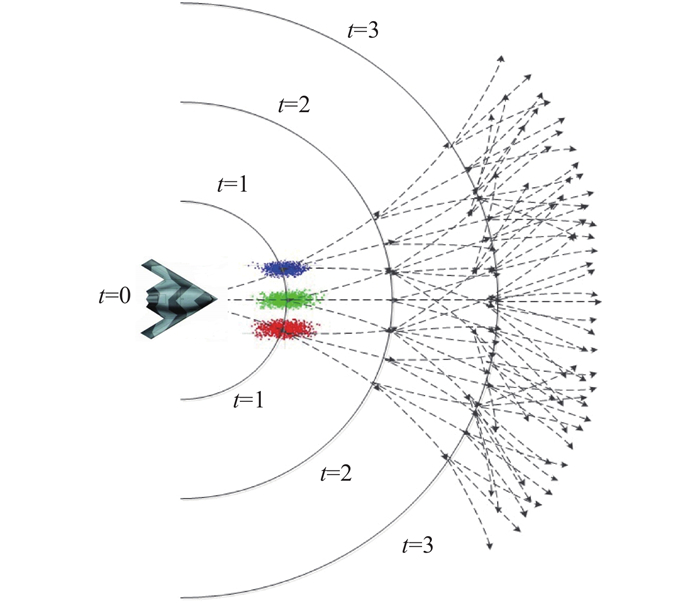
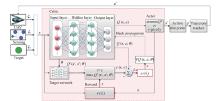
Fig 5
DRL-based motion planning architecture"
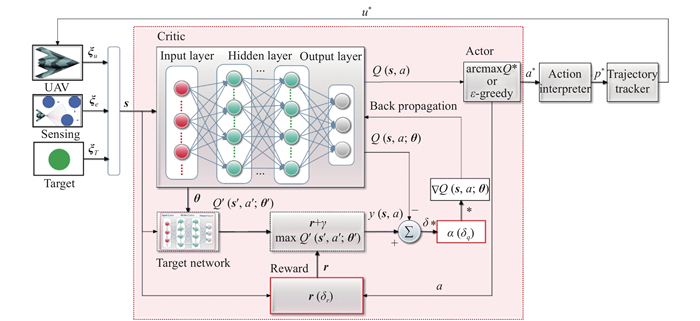
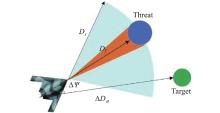
Fig 6
Relative situations among UAV, threat, and target"
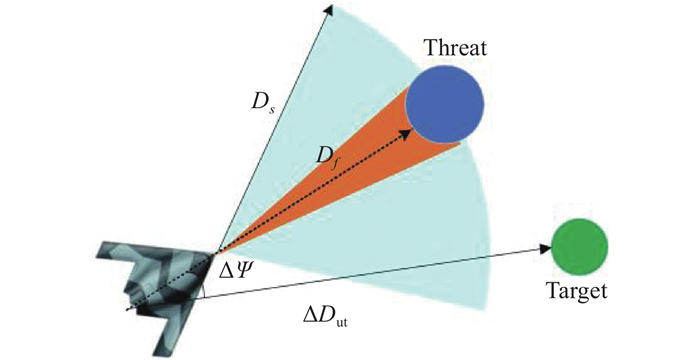

Fig 7
Training and test environment"

Table 1
Experiments and algorithms"
| Name | Definition of algorithms |
| DQN | DQN with an intermediate reward and a stable learning rate |
| DQN with DA1 | DQN with an intermediate reward and a variable learning rate |
| DQN with DA2 | DQN with a difference amplified reward and a stable learning rate |
| DQN with DA3 | DQN with a difference amplified reward and a variable learning rate |
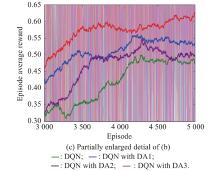
Fig 8
Convergence curves of the four different algorithms"
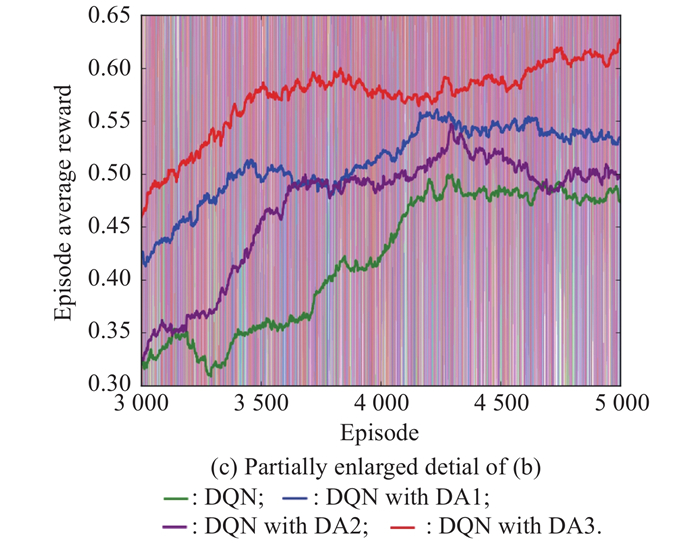
Table 2
Results of algorithms"
| Controller | Hit rate at final convergence | Episode number when the hit rate first reaches 80% | |||||||
| +Null | +DA1 | +DA2 | +DA3 | +Null | +DA1 | +DA2 | +DA3 | ||
| DQN | 0.721 | 0.844 | 0.795 | 0.894 | ? | 3995 | 4397 | 3084 | |
| Double DQN | 0.812 | 0.853 | 0.867 | 0.925 | 4983 | 3567 | 3854 | 2902 | |
| Dueling DQN | 0.854 | 0.863 | 0.910 | 0.956 | 4125 | 3458 | 3541 | 2756 | |

Fig 9
Trajectories of the UAV with different controllers while flying across environments with different threat densities"


Fig 16
"
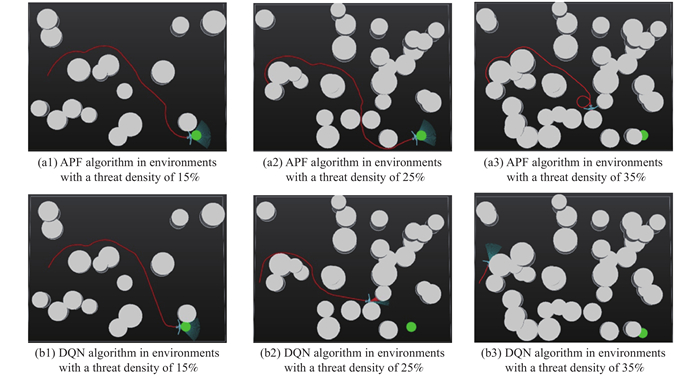
Table 3
Trajectory parameters of the four controllers"
| Controller | Environment with a threat density of 15% | Environment with a threat density of 25% | Environment with a threat density of 35% | |||||
| Flight time/s | Path length/m | Flight time/s | Path length/m | Flight time/s | Path length/m | |||
| APF | 21.0 | 420 | 24.1 | 482 | Crash | Crash | ||
| DQN | 20.0 | 400 | Crash | Crash | Crash | Crash | ||
| DQN with DA1 | 19.0 | 380 | 20.1 | 402 | Crash | Crash | ||
| DQN with DA2 | 18.8 | 376 | 19.7 | 394 | 23.1 | 462 | ||
| DQN with DA3 | 15.8 | 316 | 17.3 | 346 | 22.1 | 442 | ||

Fig 10
Trajectories of the UAV with different controllers while facing pop-up threats"

Table 4
Trajectory parameters of the four controllers"
| Controller | No pop-up threat | One pop-up threat | Two pop-up threats | |||||
| Flight time/s | Path length/m | Flight time/s | Path length/m | Flight time/s | Path length/m | |||
| APF | 26.2 | 524 | Crash | Crash | Crash | Crash | ||
| DQN | 23.0 | 460 | Crash | Crash | Crash | Crash | ||
| DQN with DA1 | 21.0 | 420 | Crash | Crash | Crash | Crash | ||
| DQN with DA2 | 19.1 | 382 | 20.1 | 402 | Crash | Crash | ||
| DQN with DA3 | 18.9 | 378 | 19.6 | 392 | 22.1 | 442 | ||

Fig 10
"


Fig 11
Trajectories of the UAV with different controllers while facing moving threats"

Table 5
Trajectory parameters of the four controllers"
| Controller | Low-speed threat | Medium-speed threat | High-speed threat | |||||
| Flight time/s | Path length/m | Flight time/s | Path length/m | Flight time/s | Path length/m | |||
| APF | 22.2 | 444 | Crash | Crash | Crash | Crash | ||
| DQN | 20.3 | 406 | Crash | Crash | Crash | Crash | ||
| DQN with DA1 | 19.2 | 384 | 18.7 | 374 | Crash | Crash | ||
| DQN with DA2 | 19.1 | 382 | 18.2 | 364 | Crash | Crash | ||
| DQN with DA3 | 18.7 | 374 | 17.9 | 358 | 18.5 | 370 | ||

Fig 12
Trajectories of the UAV with different controllers while facing the moving target"
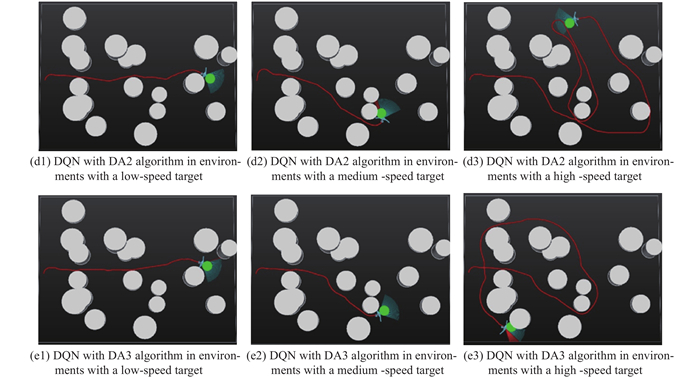

Fig 12
"

Table 6
Trajectory parameters of the four controllers"
| Controller | Low-speed target (10 m/s) | Medium-speed target (15 m/s) | High-speed target (20 m/s) | |||||
| Flight time/s | Path length/m | Flight time/s | Path length/m | Flight time/s | Path length/m | |||
| APF | 24.5 | 490 | 20.8 | 416 | 48.1 | 962 | ||
| DQN | 22.0 | 440 | 30.8 | 616 | Crash | Crash | ||
| DQN with DA1 | 19.3 | 386 | 25.6 | 512 | Crash | Crash | ||
| DQN with DA2 | 17.3 | 346 | 16.0 | 320 | 61.9 | 1 238 | ||
| DQN with DA3 | 16.9 | 338 | 14.6 | 292 | 43.9 | 878 | ||
| 1 | STEVENS R C, SADJADI F A, et al. Small unmanned aerial vehicle (UAV) real-time intelligence, surveillance and reconnaissance (ISR) using onboard pre-processing. Proc. of the SPIE, 2008: 6967. |
| 2 | DARRAH M, NILAND W, STOLARIK B, et al. UAV cooperative task assignments for a SEAD mission using genetic algorithms. Proc. of AIAA Guidance, Navigation, and Control Conference and Exhibit, 2006. DOI: 10.2514/6.2006-6456. |
| 3 | TOMIC T, SCHMID K, LUTZ P, et al Toward a fully autonomous UAV: research platform for indoor and outdoor urban search and rescue. IEEE Robotics & Automation Magazine, 2012, 19 (3): 46- 56. |
| 4 |
SHAKHATREH H, SAWALMEH A, AL-FUQAHA A, et al Unmanned aerial vehicles (UAVs): a survey on civil applications and key research challenges. IEEE Access, 2019, 7, 48572- 48634.
doi: 10.1109/ACCESS.2019.2909530 |
| 5 | WAN K F, GAO X G, HU Z J, et al. A RDA-based deep reinforcement learning approach for autonomous motion planning of UAV in dynamic unknown environments. Proc. of the 4th International Conference on Control Engineering and Artificial Intelligence, 2020. DOI: 10.26914/c.cnkihy.2020.002792. |
| 6 | IMANBERDIYEV N, FU C, KAYACAN E, et al. Autonomous navigation of UAV by using real-time model-based reinforcement learning. Proc. of the 14th International Conference on Control, Automation, Robotics and Vision, 2016: 1−6. |
| 7 |
WAN K F, GAO X G, HU Z J, et al Robust motion control for UAV in dynamic uncertain environments using deep reinforcement learning. Remote Sensing, 2020, 12 (4): 640- 661.
doi: 10.3390/rs12040640 |
| 8 | CHEE K Y, ZHONG Z W Control, navigation and collision avoidance for an unmanned aerial vehicle. Sensors and Actuators A: Physical, 2013, 190 (1): 66- 76. |
| 9 | PANAGOU D A distributed feedback motion planning protocol for multiple unicycle agents of different classes. IEEE Trans. on Automatic Control, 2016, 62 (3): 1178- 1193. |
| 10 | ISRAELSEN J, BEALL M, BAREISS D, et al. Automatic collision avoidance for manually tele-operated unmanned aerial vehicles. Proc. of the IEEE International Conference on Robotics and Automation, 2014: 6638−6643. |
| 11 | YANG X, DING M Y, ZHOU C. Fast marine route planning for UAV using improved sparse A* algorithm. Proc. of the 4th International Conference on Genetic and Evolutionary Computing, 2011: 190−193. |
| 12 | DUAN H B, PEI L. UAV path planning. Berlin: Springer, 2014. |
| 13 |
WAN K F, GAO X G, LI B Using approximate dynamic programming for multi-ESM scheduling to track ground moving targets. Journal of Systems Engineering and Electronics, 2018, 29 (1): 74- 85.
doi: 10.21629/JSEE.2018.01.08 |
| 14 |
YANG Q M, ZHANG J D, SHI G Q Modeling of UAV path planning based on IMM under POMDP framework. Journal of Systems Engineering and Electronics, 2019, 30 (3): 545- 554.
doi: 10.21629/JSEE.2019.03.12 |
| 15 |
DONG Z N, ZHANG R L, CHEN Z J, et al Study on UAV path planning approach based on fuzzy virtual force. Chinese Journal of Aeronautics, 2010, 23 (3): 341- 350.
doi: 10.1016/S1000-9361(09)60225-9 |
| 16 | BREZOESCU A, ESPINOZA T, CASTILLO P, et al Adaptive trajectory following for a fixed-wing UAV in presence of crosswind. Journal of Intelligent & Robotic Systems, 2013, 69 (1/4): 257- 271. |
| 17 |
FADLULLAH Z M, TAKAISHI D, NISHIYAMA H, et al A dynamic trajectory control algorithm for improving the communication throughput and delay in UAV-aided networks. IEEE Network, 2016, 30 (1): 100- 105.
doi: 10.1109/MNET.2016.7389838 |
| 18 | GEE T, JAMES J, MARK W, et al. Lidar guided stereo simultaneous localization and mapping (SLAM) for UAV outdoor 3-D scene reconstruction. Proc. of the International Conference on Image and Vision Computing, 2016: 1−6. |
| 19 | PANCHPOR A A, SHUE S, CONRAD JM, et al. A survey of methods for mobile robot localization and mapping in dynamic indoor environments. Proc. of the Conference on Signal Processing & Communication Engineering Systems, 2018: 138−144. |
| 20 | ALTAN A, BAYRAKTAR K, HACIOGLU R, et al. Simultaneous localization and mapping of mines with unmanned aerial vehicle. Proc. of the 24th Signal Processing and Communication Application Conference, 2016: 1433−1436. |
| 21 | FU C H, OLIVARES M, SUAREZ R, et al Monocular visual-inertial slam-based collision avoidance strategy for fail-safe UAV using fuzzy logic controllers. The International Journal of Robotics Research, 2014, 73 (4): 513- 533. |
| 22 | SUTTON R S, BARTO A G. Reinforcement learning: an introduction. 2nd ed. Cambridge, US: MIT Press, 2017. |
| 23 | KERSANDT K. Deep reinforcement learning as control method for autonomous UAV. Barcelona, Spain: University of Catalonia, 2017 |
| 24 |
VOLODYMYR M, KORAY K, David S, et al Human-level control through deep reinforcement learning. Nature, 2015, 518 (7540): 529- 533.
doi: 10.1038/nature14236 |
| 25 | HASSELT H V, GUEZ A, SILVER D. Deep reinforcement learning with double Q-learning. Proc. of the 30th AAAI Conference on Artificial Intelligence, 2016. arXiv: 1509.06461. |
| 26 | WANG Z Y, SCHAUL T, MATTEO H, et al. Dueling network architectures for deep reinforcement learning. Proc. of the 33rd International Conference on Machine Learning, 2016, 48: 1995–2003. |
| 27 | FAN D D, THEODOROU E, REEDER J, et al. Model-based stochastic search for large scale optimization of multi-agent UAV swarms. Proc. of the IEEE Symposium Series on Computational Intelligence, 2017. arXiv: 1803.01106. |
| 28 |
WANG C, WANG J, SHEN Y, et al Autonomous navigation of UAVs in large-scale complex environments: a deep reinforcement learning approach. IEEE Trans. on Vehicular Technology, 2019, 68 (3): 2124- 2136.
doi: 10.1109/TVT.2018.2890773 |
| 29 | ALEJANDRO R R, CARLOS S, HRIDAY B, et al A deep reinforcement learning strategy for UAV autonomous landing on a moving platform. Journal of Intelligent & Robotic Systems, 2018, 93, 351- 366. |
| 30 | KOCH W, MANCUSO R, WEST R, et al Reinforcement learning for uav attitude control. ACM Trans. on Cyber-Physical Systems, 2019, 3 (2): 1- 21. |
| 31 | LILLICRAP T T, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning. arXiv, 2015. arXiv: 1509.02971. |
| 32 | SCHULMAN J, LEVINE S, MORITZ P, et al. Trust region policy optimization. Proc. of the 32nd International Conference on Machine Learning, 2015. arXiv:1502.05477. |
| 33 | SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms. arXiv, 2017. arXiv:1707.06347. |
| 34 | HERNANDEZ E G, ARANDA E. Convergence and collision avoidance in formation control: a survey of the artificial potential functions approach. ALKHATEEB F, MAGHAYREH A E, DOUSH A I, ed. Multi-agent systems-modeling, control, programming, simulations and applications. InTechOpen, 2011: 103−126. |
| 35 | LUCA A D, ORIOLO G. Local incremental planning for nonholonomic mobile robots. Proc. of the IEEE International Conference on Robotics and Automation, 1994. DOI: 10.1109/ROBOT.1994.351003. |
| 36 |
LOIZOU S G, KYRIAKOPOULOS K J Navigation of multiple kinematically constrained robots. IEEE Trans. on Robotics, 2008, 24 (1): 221- 231.
doi: 10.1109/TRO.2007.912092 |
| 37 | KIM J O, KHOSLA P K. Real-time obstacle avoidance using harmonic potential functions. IEEE Trans. on Robotics and Automation, 1992, 8(3): 338–349. |
| 38 | LAWRENCE D A, FREW E W, PISANO W Lyapunov guidance vector fields for autonomous unmanned aircraft flight control. Journal of Guidance, Control, and Dynamics, 2012, 31 (5): 1220- 1229. |
| 39 |
FREW E W, LAWRENCE D A, MORRIS S Coordinated standoff tracking of moving targets using Lyapunov guidance vector. Journal of Guidance, Control, and Dynamics, 2008, 31 (2): 290- 306.
doi: 10.2514/1.30507 |
| 40 | PARK S Circling over a target with relative side bearing. Journal of Guidance Control & Dynamics, 2016, 39 (6): 1- 7. |
| 41 | JUNG W, LIM S, LEE D, et al Unmanned aircraft vector field path following with arrival angle control. Journal of Intelligent & Robotic Systems, 2016, 84, 311- 325. |
| 42 | NAMHOON C, YOUDAN K, SANGHYUK P. Three-dimensional nonlinear differential geometric path-following guidance law. Journal of Guidance, Control, and Dynamics, 2015, 38(12). DOI: https://doi.org/10.2514/1.G001060. |
| 43 |
SAMUELSON W, ZECKHAUSER R Status quo bias in decision making. Journal of Risk and Uncertainty, 1988, 1, 7- 59.
doi: 10.1007/BF00055564 |
| 44 | DIXON C. Controlled mobility of unmanned aircraft chains to optimize network capacity in realistic communication environments. Colorado, US: University of Colorado, 2010. |
| 45 | QUINTERO S, COLLINS G, HESPANHA J. Flocking with fixed-wing UAVs for distributed sensing: a stochastic optimal control approach. Proc. of the American Control Conference, 2013. DOI: 10.1109/ACC.2013.6580133. |
| 46 |
WU G F, GAO X G, FU X W Mobility control of unmanned aerial vehicle as communication relay in airborne multi-user systems. Chinese Journal of Aeronautics, 2019, 32 (6): 1520- 1529.
doi: 10.1016/j.cja.2019.02.010 |
| 47 | HORGAN D, QUAN J, BUDDEN D, et al. Distributed prioritized experience replay. arXiv, 2018. arXiv:1803.00933. |
| 48 | IVANOV S, YAKONOV A. Modern deep reinforcement learning algorithms. arXiv preprint, arXiv:1906.10025, 2019. |
| 49 | HU Z J, WAN K F, GAO X G, et al A dynamic adjusting reward function method for deep reinforcement learning with adjustable parameters. Mathematical Problems in Engineering, 2019, 7619483. |
| [1] | Bohao LI, Yunjie WU, Guofei LI. Hierarchical reinforcement learning guidance with threat avoidance [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1173-1185. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||