
Journal of Systems Engineering and Electronics ›› 2021, Vol. 32 ›› Issue (5): 1097-1110.doi: 10.23919/JSEE.2021.000094
• ELECTRONICS TECHNOLOGY • Previous Articles Next Articles
Yuanrong TIAN1,*( ), Xing WANG2()
), Xing WANG2()
Received:2020-07-22
Online:2021-10-18
Published:2021-11-04
Contact:
Yuanrong TIAN
E-mail:tianyuanrong20@nudt.edu.cn;xwang_mail@yeah.net
About author:Supported by:Yuanrong TIAN, Xing WANG. Learning a discriminative high-fidelity dictionary for single channel source separation[J]. Journal of Systems Engineering and Electronics, 2021, 32(5): 1097-1110.
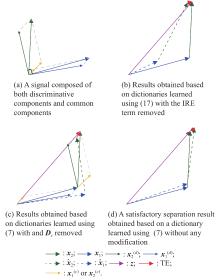
Fig 1
Illustration of the effects of the IRE and the common sub-dictionary on DL"
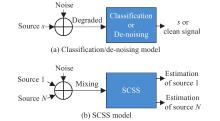
Fig 2
Structures of the classification/de-noising model and the SCSS model"
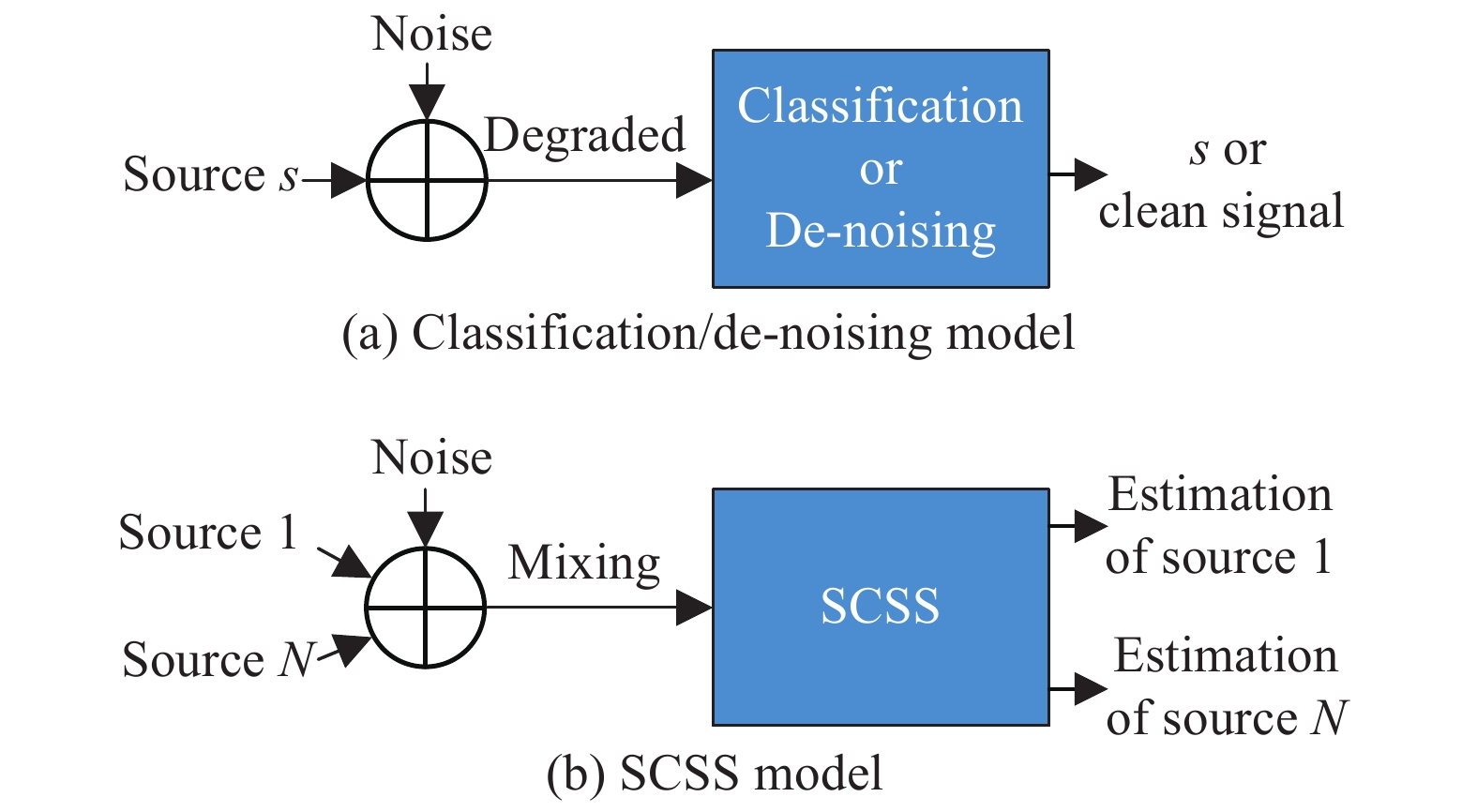
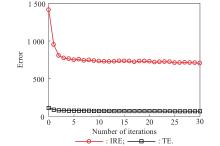
Fig 3
Curves of the error values associated with (7) in the processing of a small set of the experimental database"
Table 1
Comparison of K-SVD-, DDL-, DSNMF-LS and DHFDL-based SCSS for various values of ${\boldsymbol{l}}$ and η "
| Method | l | SER/dB | SIR/dB | |||||||||
| η=0.06 | η=0.07 | η=0.08 | η=0.1 | η=0.15 | η=0.06 | η=0.07 | η=0.08 | η=0.1 | η=0.15 | |||
| K-SVD | 60 | 0.75 | 1.39 | 1.81 | 1.82 | 1.98 | 6.56 | 7.83 | 8.67 | 8.93 | 9.35 | |
| 70 | 0.48 | 1.25 | 1.72 | 1.91 | 2.02 | 5.77 | 6.98 | 8.32 | 8.79 | 9.06 | ||
| 80 | 0.92 | 1.31 | 1.66 | 1.91 | 2.07 | 5.40 | 7.01 | 7.61 | 8.34 | 9.02 | ||
| 100 | 1.03 | 1.33 | 1.47 | 1.67 | 1.84 | 5.55 | 6.49 | 7.21 | 7.50 | 7.89 | ||
| 120 | 1.09 | 1.33 | 1.53 | 1.67 | 1.79 | 5.50 | 6.51 | 6.91 | 7.16 | 7.57 | ||
| DDL | 60 | 2.15 | 2.09 | 2.03 | 2.00 | 1.95 | 9.21 | 8.95 | 9.07 | 9.25 | 9.34 | |
| 70 | 2.12 | 2.17 | 2.13 | 2.09 | 2.07 | 9.40 | 9.32 | 9.18 | 9.34 | 9.50 | ||
| 80 | 2.12 | 2.18 | 2.17 | 2.11 | 2.12 | 9.68 | 9.23 | 9.30 | 9.07 | 9.38 | ||
| 100 | 2.08 | 2.12 | 2.11 | 2.16 | 2.16 | 9.96 | 9.42 | 9.23 | 9.29 | 9.25 | ||
| 120 | 2.00 | 2.11 | 2.17 | 2.22 | 2.24 | 9.87 | 9.71 | 9.72 | 9.70 | 9.69 | ||
| DSNMF-LS | 60 | 2.00 | 2.11 | 2.19 | 2.21 | 2.19 | 8.98 | 9.12 | 9.38 | 9.46 | 9.42 | |
| 70 | 2.08 | 2.22 | 2.26 | 2.26 | 2.20 | 9.00 | 9.22 | 9.46 | 9.61 | 9.57 | ||
| 80 | 2.10 | 2.30 | 2.35 | 2.30 | 2.21 | 9.40 | 9.76 | 9.92 | 10.09 | 9.65 | ||
| 100 | 2.00 | 2.10 | 2.19 | 2.16 | 2.17 | 9.48 | 9.62 | 9.82 | 9.79 | 10.00 | ||
| 120 | 1.96 | 1.98 | 2.12 | 2.14 | 2.15 | 9.03 | 9.54 | 9.76 | 9.84 | 9.99 | ||
| DHFDL | 60 | 2.56 | 2.90 | 2.87 | 2.83 | 2.83 | 9.45 | 9.26 | 8.98 | 8.75 | 8.79 | |
| 70 | 2.64 | 2.80 | 2.80 | 2.90 | 2.91 | 10.48 | 9.93 | 8.99 | 9.29 | 9.16 | ||
| 80 | 2.46 | 2.68 | 2.77 | 2.84 | 2.90 | 10.49 | 10.02 | 9.72 | 9.34 | 9.36 | ||
| 100 | 2.16 | 2.58 | 2.63 | 2.74 | 2.81 | 7.78 | 10.32 | 9.95 | 9.79 | 9.93 | ||
| 120 | 2.13 | 2.39 | 2.59 | 2.64 | 2.72 | 7.19 | 9.63 | 10.22 | 10.38 | 10.21 | ||
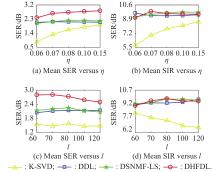
Fig 4
Comparisons of K-SVD, DDL, DSNMF-LS, and DHFDL-based SCSS with varying η and ${\boldsymbol{l}}$ values "
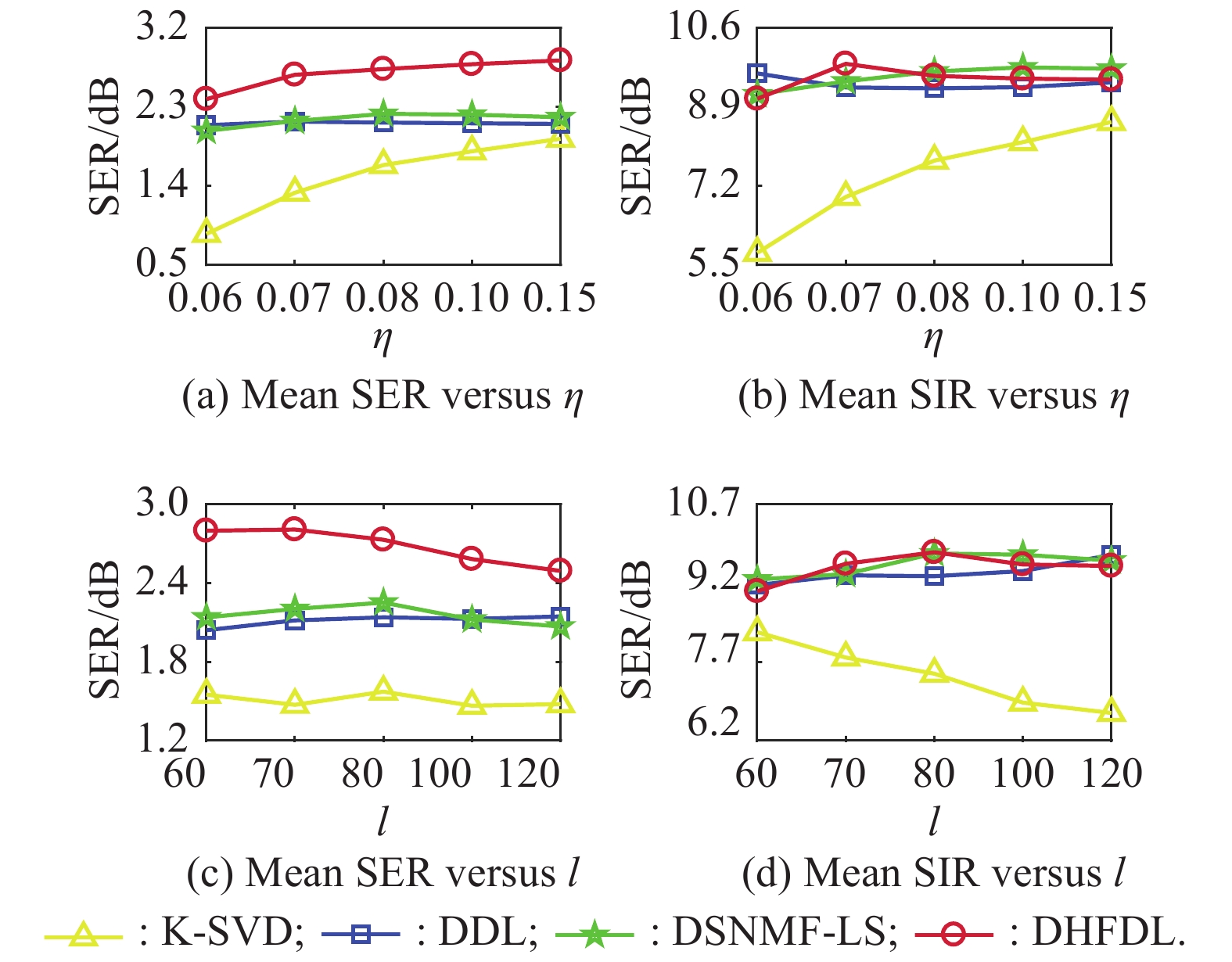
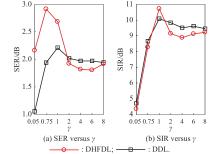
Fig 5
Comparison of the SCSS results obtained via DHFDL and DDL for different values of γ "
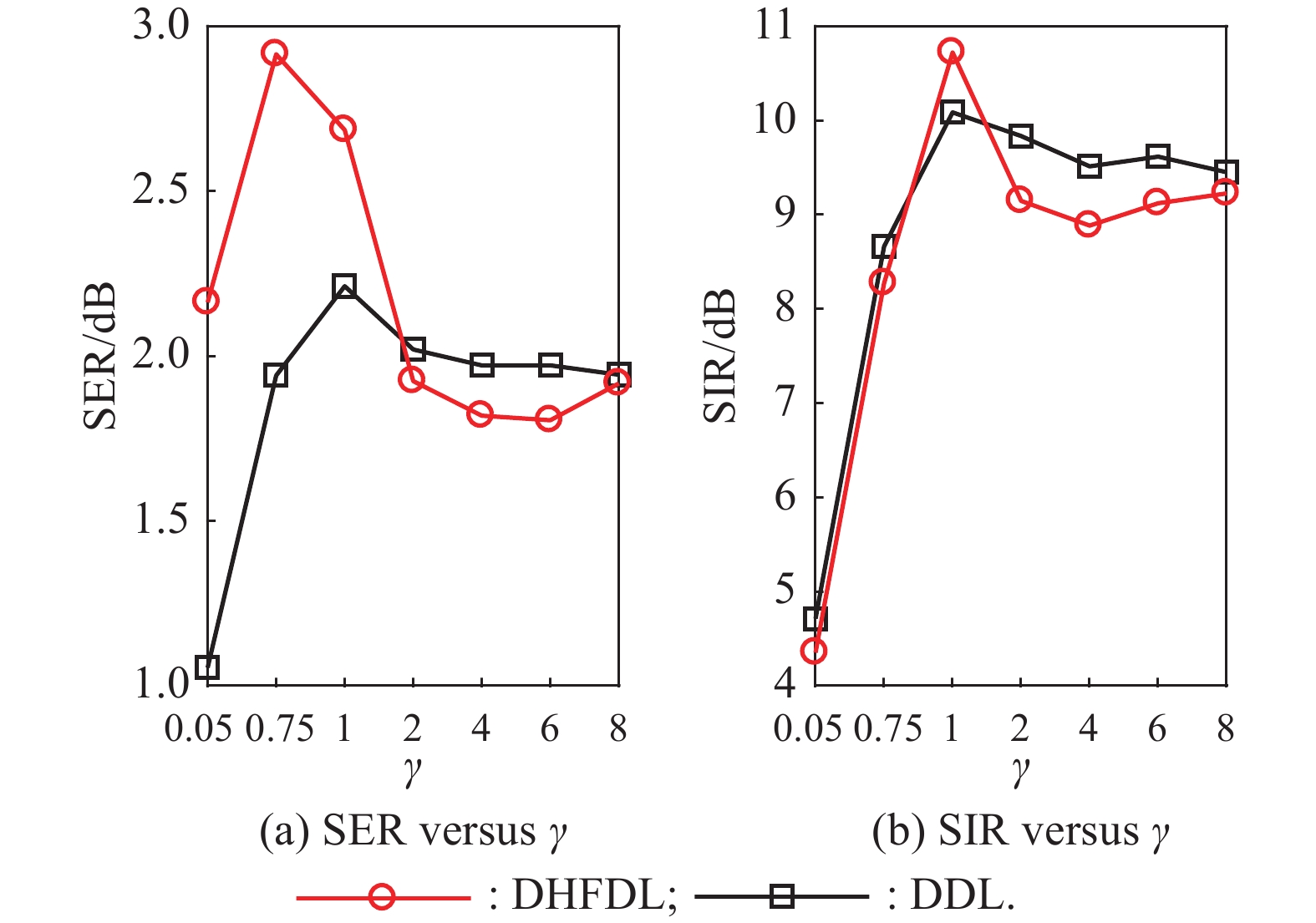
Fig 6
Separation of two underlying speech signals from a single mixed signal using the proposed SCSS method based on DHFDL"
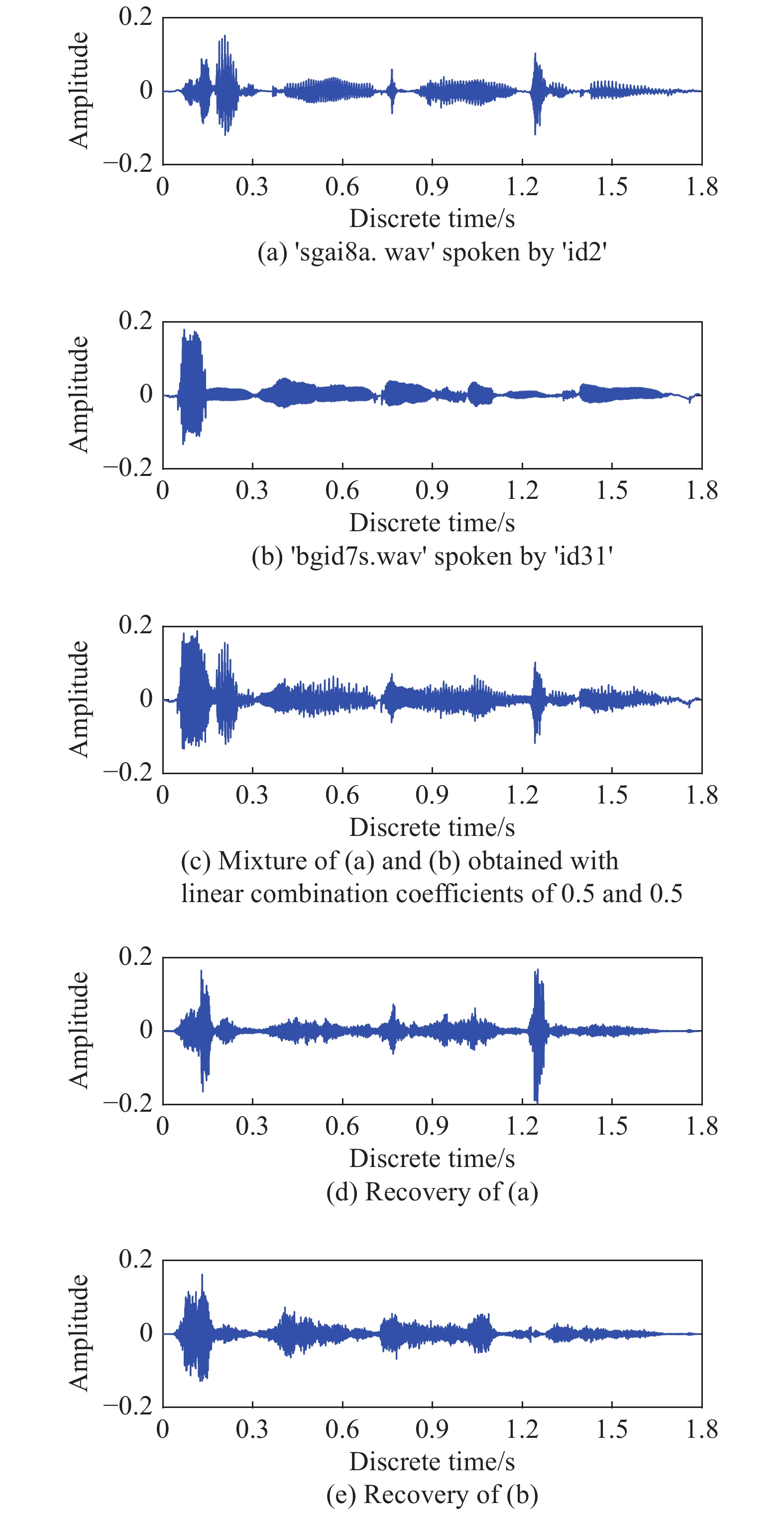
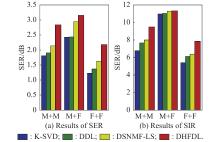
Fig 7
Performance comparison between SCSS methods based on K-SVD, DDL, DSNMF-LS and DHFDL for mixed speech signals corresponding to different gender combinations"
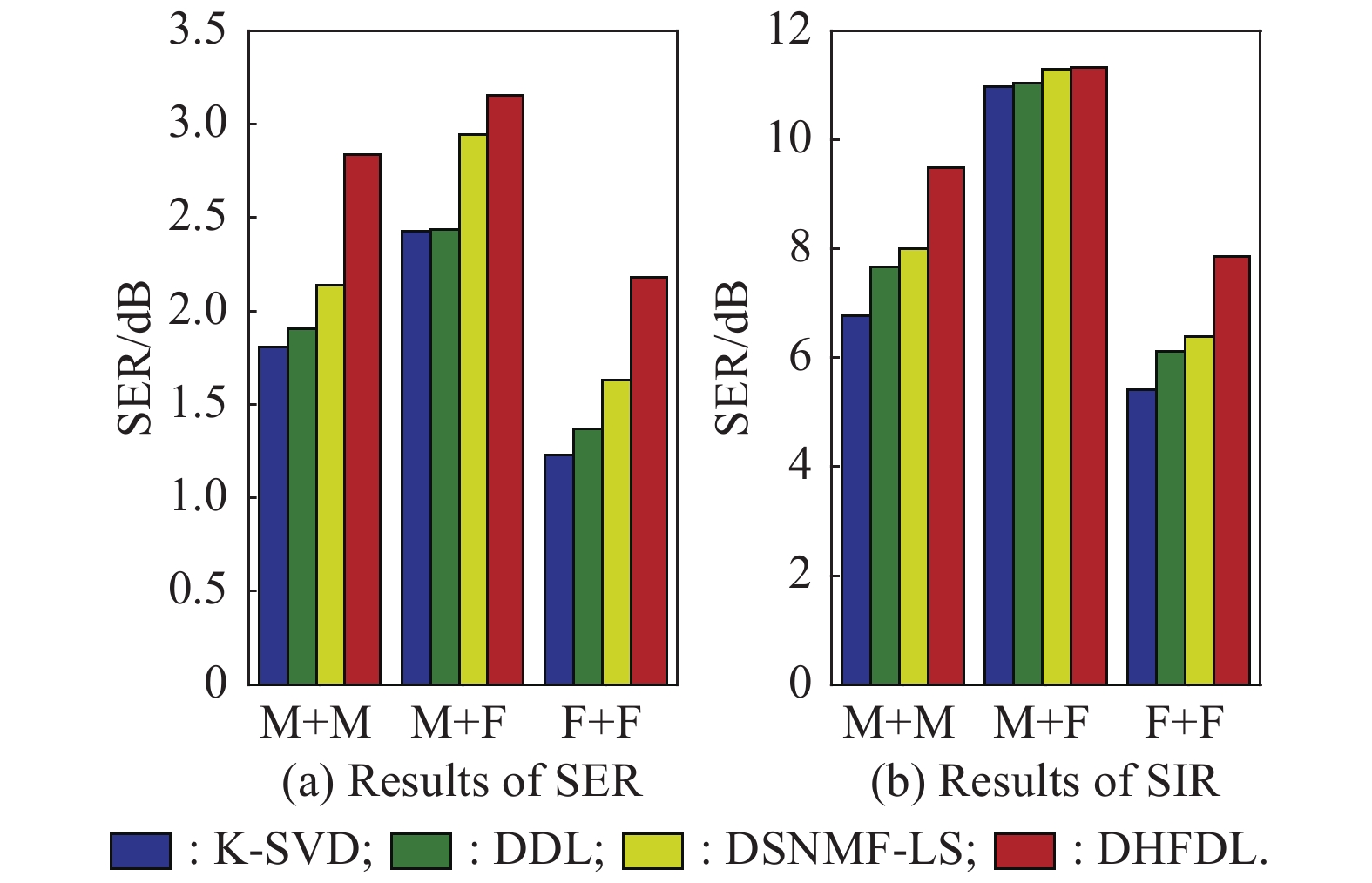
Table 2
SER and SIR results for SCSS based on different DL methods at different SSRs dB "
| SSR | SER | SIR | |||||||
| K-SVD | DDL | DSNMF-LS | DHFDL | K-SVD | DDL | DSNMF-LS | DHFDL | ||
| ?2 | 0.94 | 1.68 | 1.81 | 2.04 | 7.62 | 8.27 | 8.43 | 8.75 | |
| ?1 | 1.42 | 2.05 | 2.09 | 2.37 | 8.34 | 8.95 | 9.12 | 9.13 | |
| 0 | 2.07 | 2.12 | 2.21 | 2.90 | 9.02 | 9.38 | 9.65 | 9.36 | |
| 1 | 1.43 | 2.05 | 2.18 | 2.36 | 8.34 | 8.97 | 9.12 | 9.14 | |
| 2 | 0.96 | 1.67 | 1.69 | 1.99 | 7.67 | 8.20 | 8.43 | 8.69 | |
| Average | 1.36 | 1.91 | 2.00 | 2.33 | 8.20 | 8.75 | 8.95 | 9.01 | |
Table 3
SER and SIR results for SCSS based on different DL methods at different SNR levels dB "
| SNR | SER | SIR | |||||||
| K-SVD | DDL | DSNMF-LS | DHFDL | K-SVD | DDL | DSNMF-LS | DHFDL | ||
| ?6 | 0.10 | 0.09 | 0.13 | 0.49 | 0.78 | 0.95 | 1.20 | 2.97 | |
| ?3 | 0.27 | 0.15 | 0.20 | 0.64 | 1.50 | 1.54 | 1.78 | 3.90 | |
| 0 | 0.37 | 0.40 | 0.48 | 0.79 | 2.59 | 2.38 | 2.35 | 5.20 | |
| 3 | 0.57 | 0.87 | 0.95 | 1.00 | 3.12 | 3.10 | 3.28 | 6.02 | |
| 6 | 1.23 | 1.69 | 1.70 | 1.86 | 3.70 | 4.12 | 4.94 | 7.13 | |
| 9 | 1.98 | 2.22 | 2.48 | 2.69 | 4.84 | 5.44 | 6.88 | 7.34 | |
| Average | 0.75 | 0.90 | 0.99 | 1.24 | 2.76 | 2.92 | 3.41 | 5.43 | |
| 1 | ROWEIS S T. One microphone source separation. Advances in Neural Information Processing Systems, 2000, 13: 793–799. |
| 2 | VINCENT E, VIRTANEN T, GANNOT S. Audio source separation and speech enhancement. New York: John Wiley & Sons Press, 2018. |
| 3 | XU C, RAO W, XIAO X, et al. Single channel speech separation with constrained utterance level permutation invariant training using grid LSTM. Proc. of the International Conference on Acoustics, Speech and Signal Processing, 2018: 6–10. |
| 4 | WANG Q, WOO W L, DLAY S S, et al. Informed single channel speech separation with time-frequency exemplar GMM-HMM model. Proc. of the International Conference on Digital Signal Processing, 2015: 1130–1134. |
| 5 | YEMINY Y R, KELLER Y, GANNOT S. Single microphone speech separation by diffusion-based HMM estimation. EURASIP Journal on Audio, Speech, and Music Processing, 2016. DOI: 10.1186/s13636-016-0094-9. |
| 6 |
ZIBULEVSKY M, PEARLMUTTER B A Blind source separation by sparse decomposition in a signal dictionary. Neural Computing, 2001, 13 (4): 863- 882.
doi: 10.1162/089976601300014385 |
| 7 | GOWREESUNKER B V, TEWFIK A H. Blind source separation using monochannel overcomplete dictionaries. Proc. of the International Conference on Acoustics, Speech and Signal Processing, 2008: 33−36. |
| 8 | QIAN Y M, WENG C, CHANG X K, et al. Past review, current progress, and challenges ahead on the cocktail party problem. Frontiers of Information Technology & Electronic Engineering, 2018, 19: 40–63. |
| 9 | BAO C L, JI H, QUAN Y H, et al Dictionary learning for sparse coding: algorithms and convergence analysis. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2015, 38 (7): 1356- 1369. |
| 10 |
AHARON M, ELAD M, BRUCKSTEIN A K-SVD: an algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. on Signal Processing, 2006, 54 (11): 4311- 4322.
doi: 10.1109/TSP.2006.881199 |
| 11 |
LEE D D, SEUNG H S Learning the parts of objects by non-negative matrix factorization. Nature, 1999, 401 (6755): 788- 791.
doi: 10.1038/44565 |
| 12 | HOYER P O. Non-negative sparse coding. Proc. of the 12th Workshop on Neural Networks for Signal Processing, 2002: 557−565. |
| 13 |
YANG J C, WANG Z W, LIN Z, et al Coupled dictionary training for image super-resolution. IEEE Trans. on Image Processing, 2012, 21 (8): 3467- 3478.
doi: 10.1109/TIP.2012.2192127 |
| 14 | WEI X, SHEN H, LI Y X, et al Reconstructible nonlinear dimensionality reduction via joint dictionary learning. IEEE Trans. on Neural Networks and Learning Systems, 2018, 30 (1): 175- 189. |
| 15 | SCHMIDT M N, OLSSON R K. Single-channel speech separation using sparse non-negative matrix factorization. Proc. of the 9th International Conference on Spoken Language Processing, 2006: 2614–2617. |
| 16 |
KING B J, ATLAS L Single-channel source separation using complex matrix factorization. IEEE Trans. on Audio Speech and Language Processing, 2011, 19 (8): 2591- 2597.
doi: 10.1109/TASL.2011.2156786 |
| 17 | GRAIS E M, ERDOGAN H. Single channel speech music separation using nonnegative matrix factorization with sliding window and spectral masks. Proc. of the 12th Annual Conference on International Speech Communication Association, 2011: 1773–1776. |
| 18 | GRAIS E M, ERDOGAN H. Discriminative nonnegative dictionary learning using cross-coherence penalties for single channel source separation. Proc. of the 14th Annual Conference on International Speech Communication Association, 2013: 808–812. |
| 19 | GANG A, BIYANI P On discriminative framework for single channel audio source separation. Proc. of the 17th Annual Conference on International Speech Communication Association, 2016, 565- 569. |
| 20 |
XU Y F, BAO G Z, XU X, et al Single channel speech separation using sequential discriminative dictionary learning. Signal Processing, 2015, 106, 134- 140.
doi: 10.1016/j.sigpro.2014.07.012 |
| 21 |
SUN L H, ZHAO C, SU M, et al Single-channel blind source separation based on joint dictionary with common sub-dictionary. International Journal of Speech Technology, 2018, 21 (1): 19- 27.
doi: 10.1007/s10772-017-9469-2 |
| 22 | WANG Z, SHA F. Discriminative non-negative matrix factorization for single-channel speech separation. Proc. of the International Conference on Acoustics, Speech and Signal Processing, 2014: 3749–3753. |
| 23 | WENINGER F, ROUX J L, HERSHEY J R, et al. Discriminative NMF and its application to single-channel source separation. Proc. of the 15th Annual Conference on International Speech Communication Association, 2014: 865–869. |
| 24 |
WANG Y, WANG D L Towards scaling up classification-based speech separation. IEEE Trans. on Audio Speech and Language Processing, 2013, 21 (7): 1381- 1390.
doi: 10.1109/TASL.2013.2250961 |
| 25 | WENINGER F, HERSHEY J R, ROUX J L, et al. Discriminatively trained recurrent neural networks for single-channel speech separation. Proc. of the Global Conference on Signal and Information Processing, 2014: 577–581. |
| 26 | GRAIS E M, PLUMBLEY M D. Single channel audio source separation using convolutional denoising autoencoders. Proc. of the Global Conference on Signal and Information Processing, 2017: 1265–1269. |
| 27 | HERSHEY J R, CHEN Z, ROUX J L, et al. Deep clustering: discriminative embeddings for segmentation and separation. Proc. of the International Conference on Acoustics, Speech and Signal Processing, 2016: 31–35. |
| 28 |
WRIGHT J, YANG A Y, GANESH A, et al Robust face recognition via sparse representation. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2009, 31 (2): 210- 227.
doi: 10.1109/TPAMI.2008.79 |
| 29 | CHRISTENSEN H, BARKER J, MA N, et al. The CHiME corpus: a resource and a challenge for computational hearing in multisource environments. Proc. of the 11th Annual Conference on International Speech Communication Association, 2010: 1918–1921. |
| 30 |
VINCENT E, GRIBONVAL R, FEVOTTE C Performance measurement in blind audio source separation. IEEE Trans. on Audio Speech and Language Processing, 2006, 14 (4): 1462- 1469.
doi: 10.1109/TSA.2005.858005 |
| 31 | MAJEED S A, HUSAIN H, SAMAD S A, et al Mel frequency cepstral coefficients (MFCC) feature extraction enhancement in the application of speech recognition: a comparison study. Journal of Theoretical and Applied Information Technology, 2015, 79 (1): 38- 56. |
| [1] | Guisheng WANG, Yequn WANG, Shufu DONG, Guoce HUANG. Multiple transformation analysis for interference separation in TDCS [J]. Journal of Systems Engineering and Electronics, 2022, 33(5): 1064-1078. |
| [2] | Yang LI, Bitao JIANG, Xiaobin LI, Jing TIAN, Xiaorui SONG. Unsupervised hyperspectral unmixing based on robust nonnegative dictionary learning [J]. Journal of Systems Engineering and Electronics, 2022, 33(2): 294-304. |
| [3] | Jian WANG, Chunxia QIN, Xiufei ZHANG, Ke YANG, Ping REN. A multi-source image fusion algorithm based on gradient regularized convolution sparse representation [J]. Journal of Systems Engineering and Electronics, 2020, 31(3): 447-459. |
| [4] | Zhigang XU, Qiang MA, Feixiang YUAN. Single color image super-resolution using sparse representation and color constraint [J]. Journal of Systems Engineering and Electronics, 2020, 31(2): 266-271. |
| [5] | Wei ZHAO, Xiaofeng BIAN, Fang HUANG, Jun WANG, Mongi A ABIDI. Fast image super-resolution algorithm based on multi-resolution dictionary learning and sparse representation [J]. Journal of Systems Engineering and Electronics, 2018, 29(3): 471-482. |
| [6] | Jian ZHAO, Chao ZHANG, Shunli ZHANG, Tingting LU, Weiwen SU, Jian JIA. Pre-detection and dual-dictionary sparse representation based face recognition algorithm in non-sufficient training samples [J]. Journal of Systems Engineering and Electronics, 2018, 29(1): 196-202. |
| [7] | Long Li, Zheng Liu, and Tao Li. Radar high resolution range profile recognition via multi-SV method [J]. Systems Engineering and Electronics, 2017, 28(5): 879-889. |
| [8] | Hefei Zheng, Jing Li, Wenming Wang, Lianshan Gao, and Keming Feng. Analysis of single frequency modulation for passive hydrogen maser [J]. Systems Engineering and Electronics, 2017, 28(4): 661-. |
| [9] | Jingjing Cai, Dan Bao, and Peng Li. DOA estimation via sparse recovering from the smoothed covariance vector [J]. Systems Engineering and Electronics, 2016, 27(3): 555-561. |
| [10] | Xiang Wang, Zhitao Huang, and Yiyu Zhou. Underdetermined DOA estimation and blind separation of non-disjoint sources in time-frequency domain based on sparse representation method [J]. Journal of Systems Engineering and Electronics, 2014, 25(1): 17-25. |
| [11] | Jiajia Zhao, Zhengyuan Tang, Jie Yang, and Erqi Liu. Infrared small target detection using sparse representation [J]. Journal of Systems Engineering and Electronics, 2011, 22(6): 897-904. |
| [12] | Huanyao Dai, Xuesong Wang, and Yongzhen Li. Novel discrimination method of digital deceptive jamming in mono-pulse radar [J]. Journal of Systems Engineering and Electronics, 2011, 22(6): 910-916. |
| [13] | Yi Qingming. Blind source separation by weighted K-means clustering [J]. Journal of Systems Engineering and Electronics, 2008, 19(5): 882-887. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||