Journal of Systems Engineering and Electronics ›› 2022, Vol. 33 ›› Issue (6): 1159-1175.doi: 10.23919/JSEE.2022.000140
• • 上一篇
-
收稿日期:2021-01-11出版日期:2022-12-18发布日期:2022-12-24
A deep reinforcement learning method for multi-stage equipment development planning in uncertain environments
Peng LIU( ), Boyuan XIA(), Zhiwei YANG(), Jichao LI(), Yuejin TAN()
), Boyuan XIA(), Zhiwei YANG(), Jichao LI(), Yuejin TAN()
- 1 College of Systems Engineering, National University of Defense Technology, Changsha 410073, China
-
Received:2021-01-11Online:2022-12-18Published:2022-12-24 -
Contact:Jichao LI E-mail:liupeng81@nudt.edu.cn;xiaboyuan11@nudt.edu.cn;zhwyang88@126.com;ljcnudt@hotmail.com;yjtan@nudt.edu.cn -
About author:
LIU Peng was born in 1981. He received his M.S. degree in higher education management from the National University and Defense Technology (NUDT), Changsha, China, in 2008. He received his Ph.D. degree in management science and engineering from the NUDT, in 2020. His research interests include system of systems engineering, complex systems, and systems evaluation and optimization. E-mail: liupeng81@nudt.edu.cn
XIA Boyuan was born in 1994. He received his B.S. and M.S. degrees in management science and engineering from the National University and Defense Technology (NUDT), Changsha, China, in 2015 and 2017, respectively. He is currently a Ph.D. candidate in the College of Systems Engineering, NUDT. His research interests include system of systems engineering, complex systems, and systems evaluation and optimization E-mail: xiaboyuan11@nudt.edu.cn
YANG Zhiwei was born in 1988. He received his B.E. degree in management science and M.E. degree in management science and engineering from the National University of Defense Technology, Changsha, Hunan, China, in 2010 and 2012, respectively. He received his Ph.D. degree in computer science from Leiden University, Leiden, the Netherlands, in 2016. His research interests include studying intelligence computing and the evaluation of complex systems. E-mail: zhwyang88@126.com
LI Jichao was born in 1990. He received his B.E. degree in management science, M.E. and Ph.D. degrees in management science and engineering from the National University of Defense Technology, Changsha, Hunan, China, in 2013, 2015, and 2019, respectively. His research interests include studying complex systems with a combination of theoretical tool and data analysis, including mathematical modeling of heterogeneous information networks, applying network methodologies to analyze the development of complex system-of-systems, and data-driven studying of the collective behavior of humans. E-mail: ljcnudt@hotmail.com
TAN Yuejin was born in 1958. He received his B.E. degree in mathematics from Hunan Normal University, and M.E. degree in systems engineering from the National University of Defense Technology, Changsha, Hunan, China, in 1981 and 1985 respectively. His research interests include system of systems (SoS) requirements modeling, SoS architecture design and optimization, complex network, and system modeling and simulation.E-mail: yjtan@nudt.edu.cn -
Supported by:This work was supported by the National Natural Science Foundation of China (71690233;72001209), and the Scientific Research Foundation of the National University of Defense Technology (ZK19-16)
引用本文
. [J]. Journal of Systems Engineering and Electronics, 2022, 33(6): 1159-1175.
Peng LIU, Boyuan XIA, Zhiwei YANG, Jichao LI, Yuejin TAN. A deep reinforcement learning method for multi-stage equipment development planning in uncertain environments[J]. Journal of Systems Engineering and Electronics, 2022, 33(6): 1159-1175.
"
| Number | Variable | Symbol definition |
| 1 | Number of equipment to be developed | |
| 2 | Equipment set to be developed | |
| 3 | Cost of equipment to be developed | |
| 4 | Expected number of years for equipment development | |
| 5 | Number of years the equipment has been developed | |
| 6 | Whether the equipment has been successfully developed | |
| 7 | Number of capabilities of concern | |
| 8 | Set of capabilities of concern | |
| 9 | Expected capabilities of the equipment to be developed | |
| 10 | Capabilities after multi-stage development | |
| 11 | Final capability requirement | |
| 12 | Number of stages | |
| 13 | Current stage | |
| 14 | Coefficient to transform year to stage | |
| 14 | The investment budget for each stage | |
| 15 | Development scheme | |
| 16 | Overall capability index | |
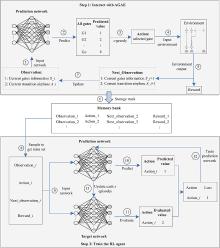
"
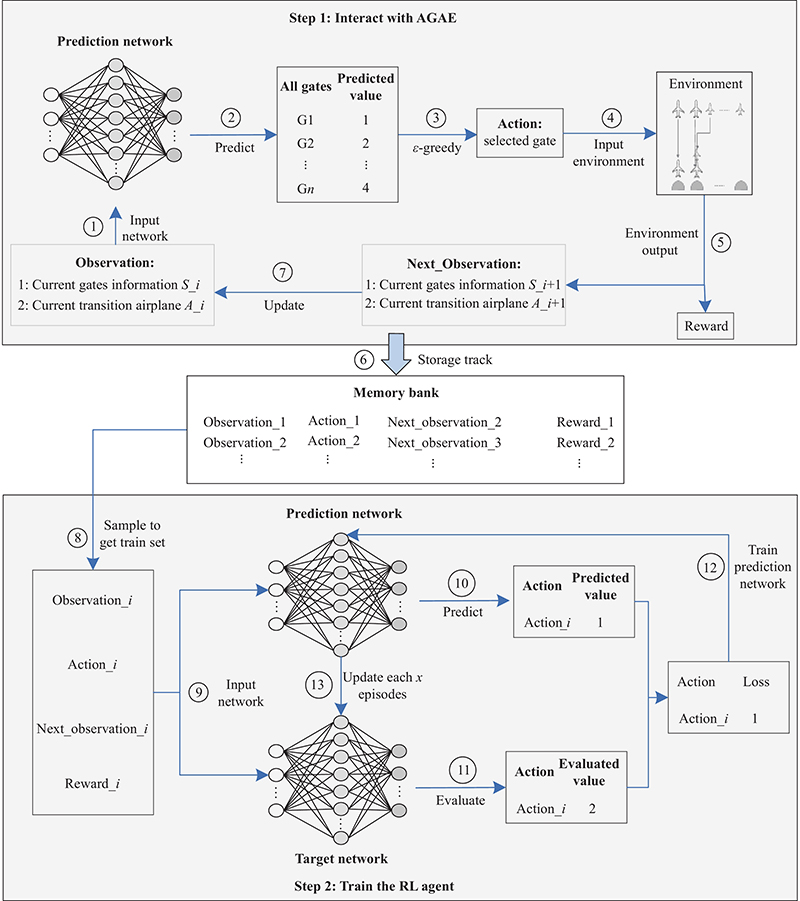
"
| Element | Data type | Normalization method | Normalized vector dimension |
| Current state of equipment development | Category | One-hot | |
| Number of years taken to develop the equipment | Scale | Divided by the maximum value | |
| Current stage | Category | One-hot | 1 |
| Investment amount at the current stage | Scale | Divided by the maximum value | 1 |
| Capability requirement | Scale | Divided by the maximum value | |
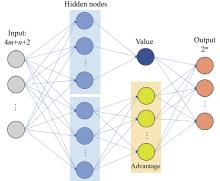
"
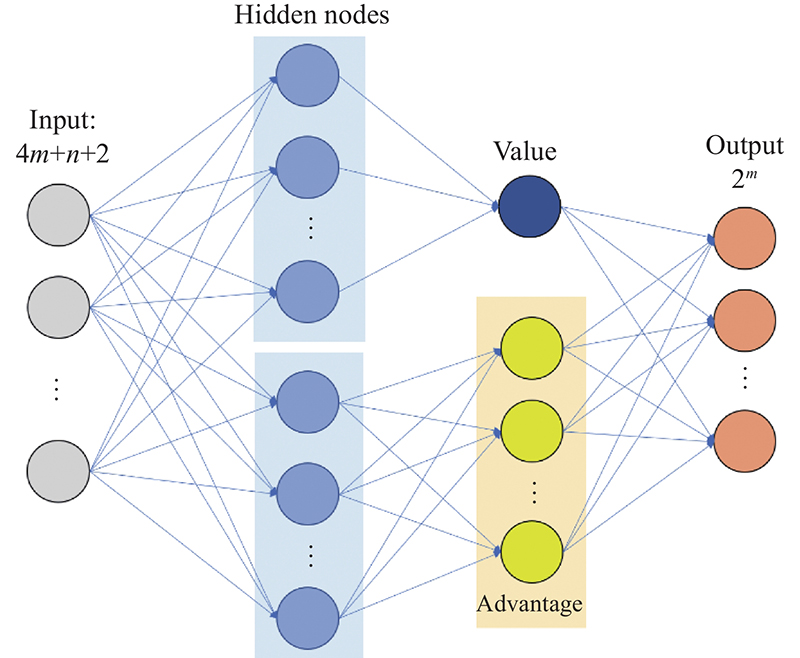
"
| Equipment to be developed | Cost (×1000 $) | Expected years of development |
| w1: Digital signal processor | 31 | 4 |
| w2: Digital image processor | 40 | 1 |
| w3: Speech synthesizer | 66 | 3 |
| w4: Low-voltage computer chip | 59 | 4 |
| w5: High-efficiency solar cell | 51 | 1 |
| w6: Digital-to-analog converter | 42 | 4 |
| w7: Analog-to-digital converter | 50 | 4 |
| w8: Frequency converter module | 60 | 1 |
| w9: Conformal phased-array antenna | 65 | 2 |
| w10: Radiofrequency mixer | 75 | 3 |
"
| Capability | w1 | w2 | w3 | w4 | w5 | w6 | w7 | w8 | w9 | w10 |
| C1 | 1 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| C2 | 0 | 1 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| C3 | 0 | 3 | 2 | 7 | 0 | 0 | 0 | 0 | 0 | 0 |
| C4 | 0 | 0 | 0 | 4 | 7 | 0 | 0 | 0 | 0 | 0 |
| C5 | 0 | 0 | 0 | 0 | 8 | 1 | 1 | 0 | 0 | 0 |
| C6 | 0 | 0 | 0 | 0 | 2 | 7 | 5 | 0 | 0 | 0 |
| C7 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 8 | 0 | 0 |
| C8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 8 | 0 |
| C9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8 | 3 | 9 |
| C10 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 |
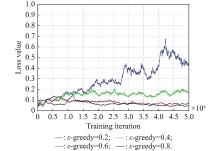
"
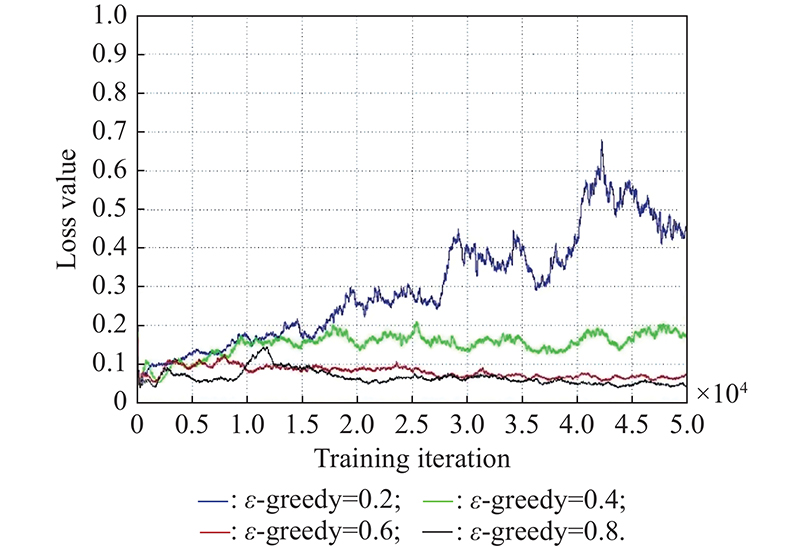
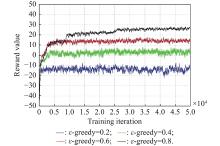
"
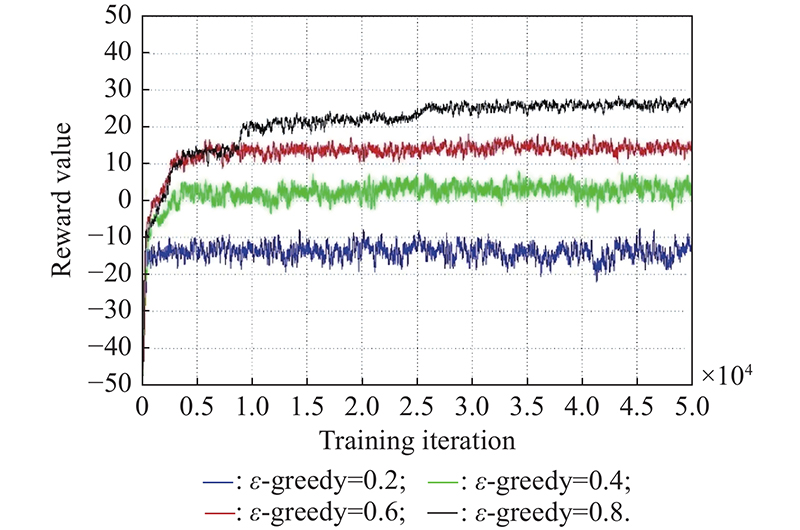
"
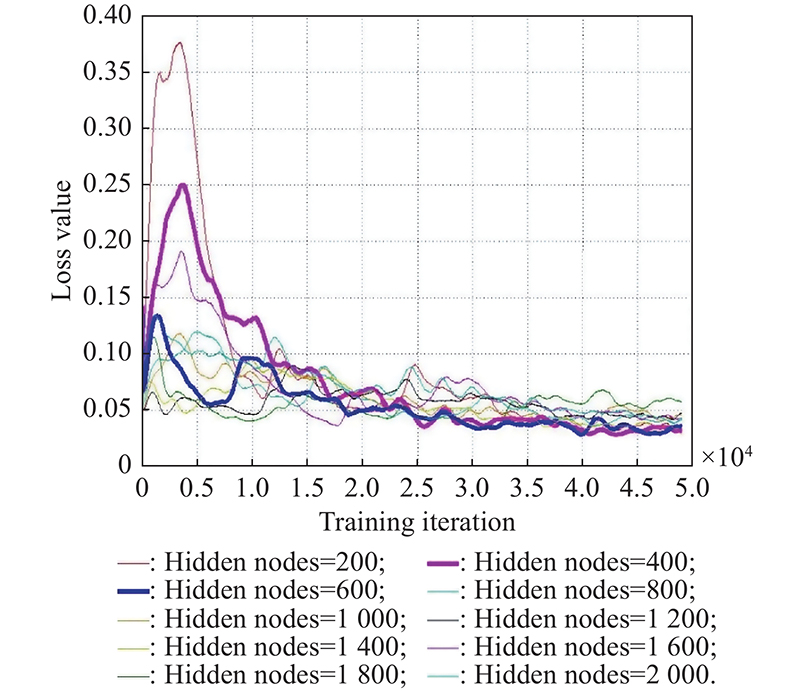
"
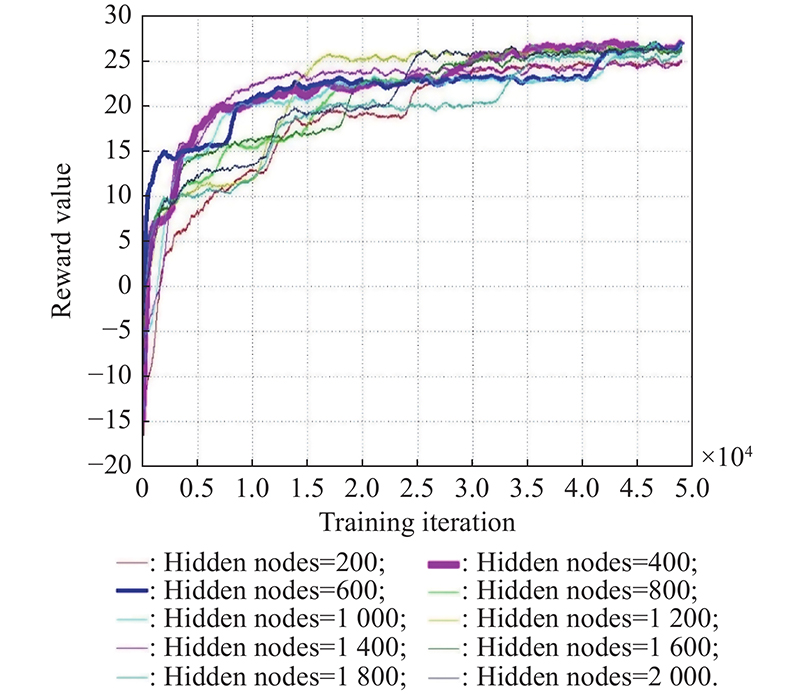
"
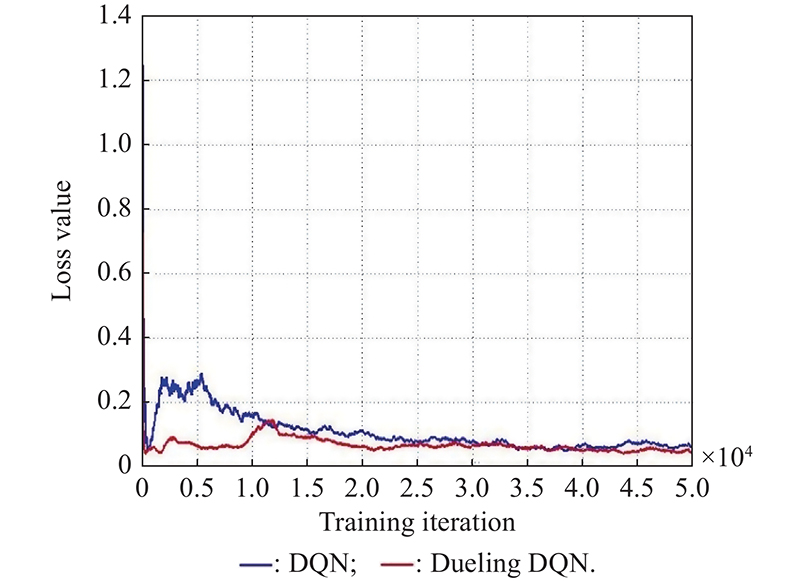
"
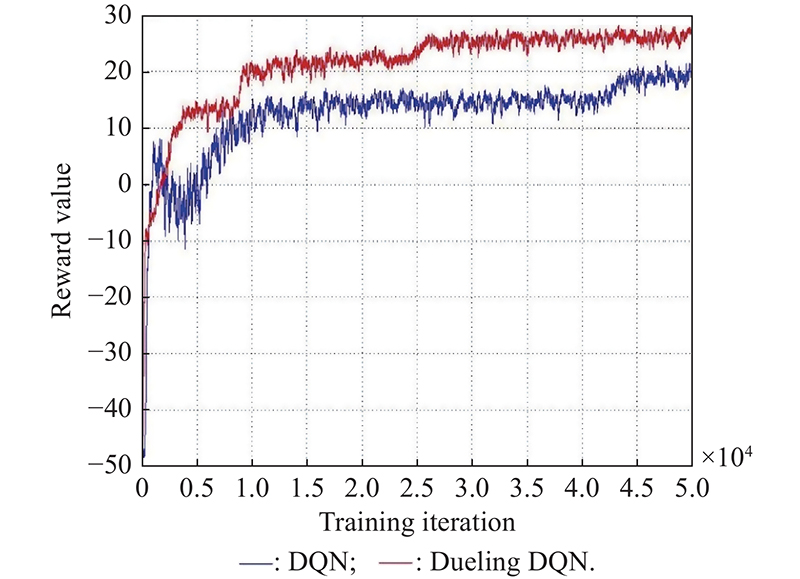
"
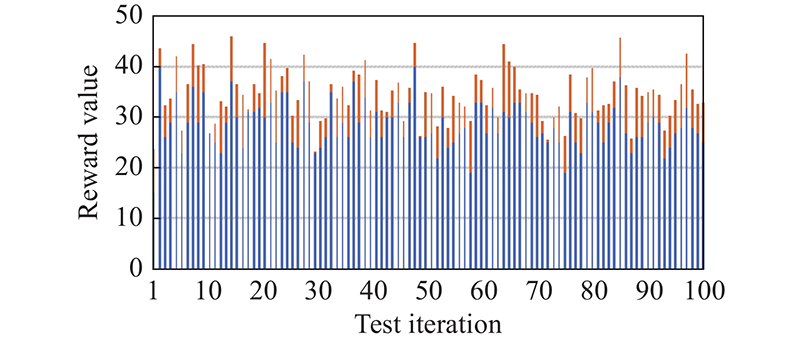
"
| Parameter | Stage | |||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| Investment amount | 71 | 59 | 60 | 63 | 68 | 73 | 63 | 79 | 70 | − |
| Required capacity | 4 | 3 | 4 | 3 | 4 | 5 | 4 | 3 | 6 | 3 |
"
| Equipment | s1 | a1 | s2 | a2 | s3 | a3 | s4 | a4 | s5 | a5 | s6 | a6 | s7 | a7 | s8 | a8 | s9 | a9 | S10 | |||
| Equipment 1 | 0 | ● | 1 | ○ | 1 | ● | 1 | ● | 1 | ● | 2 | ○ | 2 | ● | 2 | ○ | 2 | ● | 2 | |||
| Equipment 2 | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ● | 2 | ○ | 2 | ○ | 2 | ○ | 2 | ○ | 2 | ○ | 2 | |||
| Equipment 3 | 0 | ● | 1 | ○ | 1 | ● | 1 | ○ | 1 | ○ | 1 | ○ | 1 | ● | 2 | ○ | 2 | ● | 2 | |||
| Equipment 4 | 0 | ● | 1 | ● | 1 | ● | 1 | ○ | 1 | ○ | 1 | ○ | 1 | ● | 2 | 2 | ● | 2 | ||||
| Equipment 5 | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ● | 2 | ○ | 2 | ○ | 2 | ○ | 2 | |||
| Equipment 6 | 0 | ● | 1 | ○ | 1 | ● | 1 | ○ | 1 | ● | 1 | ○ | 2 | ○ | 2 | ○ | 2 | ○ | 2 | |||
| Equipment 7 | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | |||
| Equipment 8 | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ● | 2 | ○ | 2 | |||
| Equipment 9 | 0 | ○ | 0 | ● | 1 | ○ | 1 | ○ | 1 | ● | 2 | ○ | 2 | ○ | 2 | ○ | 2 | ○ | 2 | |||
| Equipment 10 | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | |||
| Development cost | 55.00 | 47.25 | 55.00 | 47.75 | 50.75 | 51.00 | 44.50 | 30.00 | 44.50 | End | ||||||||||||
"
| Parameter | Stage | |||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| Investment amount | 55 | 61 | 62 | 58 | 59 | 61 | 55 | 65 | 50 | − |
| Capacity requirement | 4 | 7 | 7 | 4 | 5 | 7 | 5 | 7 | 6 | 7 |
"
| Equipment | s1 | a1 | s2 | a2 | s3 | a3 | s4 | a4 | s5 | a5 | s6 | a6 | s7 | a7 | s8 | a8 | s9 | a9 | S10 |
| Equipment 1 | 0 | ● | 1 | ○ | 1 | ● | 1 | ● | 1 | ● | 2 | ○ | 2 | ● | 2 | ○ | 2 | ● | 2 |
| Equipment 2 | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ● | 2 | ○ | 2 | ○ | 2 | ○ | 2 | ○ | 2 | ○ | 2 |
| Equipment 3 | 0 | ● | 1 | ○ | 1 | ● | 1 | ○ | 1 | ○ | 1 | ○ | 1 | ● | 2 | ○ | 2 | ● | 2 |
| Equipment 4 | 0 | ● | 1 | ● | 1 | ● | 1 | ○ | 1 | ○ | 1 | ○ | 1 | ● | 2 | 2 | ● | 2 | |
| Equipment 5 | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ● | 2 | ○ | 2 | ○ | 2 | ○ | 2 |
| Equipment 6 | 0 | ● | 1 | ○ | 1 | ● | 1 | ○ | 1 | ● | 1 | ○ | 1 | ○ | 1 | ○ | 1 | ○ | 1 |
| Equipment 7 | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 |
| Equipment 8 | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ● | 2 | ○ | 2 |
| Equipment 9 | 0 | ○ | 0 | ● | 1 | ○ | 1 | ○ | 1 | ● | 2 | ○ | 2 | ○ | 2 | ○ | 2 | ○ | 2 |
| Equipment 10 | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 |
| Development cost | 55.00 | 47.25 | 55.00 | 47.75 | 50.75 | 51.00 | 44.50 | 60.00 | 44.50 | End | |||||||||
"
| Stage | Capability requirement | |||||||||
| Stages 1−5 | 4 | 3 | 4 | 3 | 4 | 5 | 4 | 3 | 6 | 3 |
| Stages 6−10 | 4 | 7 | 3 | 6 | 5 | 7 | 6 | 3 | 4 | 6 |
"
| Equipment | s1 | a1 | s2 | a2 | s3 | a3 | s4 | a4 | s5 | a5 | s6 | a6 | s7 | a7 | s8 | a8 | s9 | a9 | S10 |
| Equipment 1 | 0 | ● | 1 | ● | 1 | ○ | 1 | ○ | 1 | ○ | 1 | ○ | 1 | ● | 1 | ● | 2 | ○ | 2 |
| Equipment 2 | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ● | 2 | ○ | 2 | ○ | 2 | ○ | 2 | ○ | 2 | ○ | 2 |
| Equipment 3 | 0 | ● | 1 | ● | 1 | ○ | 1 | ○ | 1 | ○ | 1 | ○ | 1 | ○ | 1 | ● | 2 | ○ | 2 |
| Equipment 4 | 0 | ● | 1 | ● | 1 | ● | 1 | ○ | 1 | ○ | 1 | ○ | 1 | ○ | 1 | ● | 2 | ○ | 2 |
| Equipment 5 | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ● | 2 | ○ | 2 | ○ | 2 | ○ | 2 | ○ | 2 |
| Equipment 6 | 0 | ● | 1 | ○ | 1 | ● | 1 | ● | 1 | ○ | 1 | ○ | 1 | ● | 2 | ○ | 2 | ○ | 2 |
| Equipment 7 | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 |
| Equipment 8 | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ● | 2 | ○ | 2 | ○ | 2 | ● | 2 |
| Equipment 9 | 0 | ○ | 0 | ○ | 0 | ● | 1 | ○ | 1 | ○ | 1 | ○ | 1 | ● | 2 | ○ | 2 | ○ | 2 |
| Equipment 10 | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 | ○ | 0 |
| Development cost | 55.00 | 44.50 | 57.75 | 50.50 | 51.00 | 60.00 | 50.75 | 44.50 | 60.00 | End | |||||||||
| 1 | LORELL M A, LOWELL J, YOUNOSSI O. Evolutionary acquisition: implementation challenges for defense space programs. Santa Monica: Rand Corporation, 2006. |
| 2 | LORELL M A, JULIA F L, OBAID Y. Evolutionary acquisition is a promising strategy, but has been difficult to implement. Santa Monica: Rand Corporation, 2006. |
| 3 | SILBERGLITT R, SHERRY L. A decision framework for prioritizing industrial materials research and development. Santa Monica: Rand Corporation, 2002. |
| 4 | PREISS B, GREENE L, KRIEBEL J, et al. Air force research laboratory space technology strategic investment model: analysis and outcomes for warfighter capabilities. Proc. of the Modeling & Simulation for Military Applications, 2006. DOI: 10.1117/12.657389. |
| 5 | FEINBERG E A, SHWARTZ A. Handbook of Markov decision processes: methods and applications. New York: Springer Science & Business Media, 2002. |
| 6 | LIU B D, ZHAO R Q, WANG G. Uncertain programming with application. Beijing: Tsinghua University Press, 2005. |
| 7 | BIRGE J R, LOUVEAUX F. Introduction to stochastic programming. New York: Springer Science & Business Media, 2011. |
| 8 | KALL P, WALLACE S W. Stochastic programming. Heidelberg: Springer Berlin, 1995. |
| 9 | RUSZCZYNSKI A, SHAPIRO A. Stochastic programming models. https://doi.org/10.1137/1.9780898718751.ch1. |
| 10 | SUTTON R S, BARTO A G. Reinforcement learning: an introduction. Cambridge: MIT Press, 2018. |
| 11 | MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing Atari with deep reinforcement learning. https://doi.org/10.48550/arXiv.1312.5602. |
| 12 |
MNIH V, KAVUKCUOGLU K, SILVER D, et al Human-level control through deep reinforcement learning. Nature, 2015, 518 (7540): 529- 533.
doi: 10.1038/nature14236 |
| 13 | DANTZIG G B Linear programming under uncertainty. Management Science, 1955, 1 (3): 197- 206. |
| 14 |
EPPEN G D, MARTIN R K, SCHRAGE L A scenario approach to capability planning. Operations Research, 1989, 37 (4): 517- 527.
doi: 10.1287/opre.37.4.517 |
| 15 | CHEN Z L, LI S L, TIRUPATI D A scenario-based stochastic programming approach for technology and capacity planning. Computers & Operations Research, 2002, 29 (7): 781- 806. |
| 16 |
LULLI G, SEN S A branch-and-price algorithm for multistage stochastic integer programming with application to stochastic batch-sizing problems. Management Science, 2004, 50 (6): 786- 796.
doi: 10.1287/mnsc.1030.0164 |
| 17 |
SEN S, YU L H, GENC T A stochastic programming approach to power portfolio optimization. Operations Research, 2006, 54 (1): 55- 72.
doi: 10.1287/opre.1050.0264 |
| 18 |
GENG N, JIANG Z B, CHEN F Stochastic programming based capacity planning for semiconductor wafer fab with uncertain demand and capacity. European Journal of Operational Research, 2009, 198 (3): 899- 908.
doi: 10.1016/j.ejor.2008.09.029 |
| 19 |
PINAR M C Robust scenario optimization based on downside-risk measure for multi-period portfolio selection. OR Spectrum, 2007, 29 (2): 295- 309.
doi: 10.1007/s00291-005-0023-2 |
| 20 | SHAPIRO A Stochastic programming approach to optimization under uncertainty. Mathematical Programming, 2008, 112 (1): 183- 220. |
| 21 | HØYLAND K, KAUT M, WALLACE S W. A heuristic for moment-matching scenario generation. Computational Optimization and Applications, 2003, 24(2/3): 169–185. |
| 22 |
DENIZ E, LUXHØJ J T A scenario generation method with heteroskedasticity and moment matching. The Engineering Economist, 2011, 56 (3): 231- 253.
doi: 10.1080/0013791X.2011.599918 |
| 23 |
CASEY M S, SEN S The scenario generation algorithm for multistage stochastic linear programming. Mathematics of Operations Research, 2005, 30 (3): 615- 631.
doi: 10.1287/moor.1050.0146 |
| 24 |
WETS S R L-shaped linear programs with applications to optimal control and stochastic programming. SIAM Journal on Applied Mathematics, 1969, 17 (4): 638- 663.
doi: 10.1137/0117061 |
| 25 | CARE C C, TIND J. L-shaped decomposition of two-stage stochastic programs with integer recourse. Mathematical Programming, 1998, 83(1/3): 451–464. |
| 26 |
BLOMVALL J, LINDBERG P O A riccati-based primal interior point solver for multistage stochastic programming. European Journal of Operational Research, 2002, 143 (2): 452- 461.
doi: 10.1016/S0377-2217(02)00301-6 |
| 27 |
ALONSO A A, ESCUDERO L F, GARIN A, et al An approach for strategic supply chain planning under uncertainty based on stochastic 0-1 programming. Journal of Global Optimization, 2003, 26 (1): 97- 124.
doi: 10.1023/A:1023071216923 |
| 28 |
ALONSO A, ESCUDERO L F, ORTUNO M T BFC, a branch-and-fix coordination algorithmic framework for solving some types of stochastic pure and mixed 0-1 programs. European Journal of Operational Research, 2003, 151 (3): 503- 519.
doi: 10.1016/S0377-2217(02)00628-8 |
| 29 |
BERKELAAR A, GROMICHO J A S, KOUWENBERG R, et al A primal-dual decomposition algorithm for multistage stochastic convex programming. Mathematical Programming, 2005, 104 (1): 153- 177.
doi: 10.1007/s10107-005-0575-6 |
| 30 |
SANTOSO T, AHMED S, GOETSCHALCKX M, et al A stochastic programming approach for supply chain network design under uncertainty. European Journal of Operational Research, 2005, 167 (1): 96- 115.
doi: 10.1016/j.ejor.2004.01.046 |
| 31 |
AHMED S Convexity and decomposition of mean-risk stochastic programs. Mathematical Programming, 2006, 106 (3): 433- 446.
doi: 10.1007/s10107-005-0638-8 |
| 32 |
MILLER N, RUSZCZYNSKI A Risk-averse two-stage stochastic linear programming: modeling and decomposition. Operations Research, 2011, 59 (1): 125- 132.
doi: 10.1287/opre.1100.0847 |
| 33 |
AHMED S, KING A J, PARIJA G A multi-stage stochastic integer programming approach for capacity expansion under uncertainty. Journal of Global Optimization, 2003, 26 (1): 3- 24.
doi: 10.1023/A:1023062915106 |
| 34 |
SAHINIDIS A N V An approximation scheme for stochastic integer programs arising in capacity expansion. Operations Research, 2003, 51 (3): 461- 471.
doi: 10.1287/opre.51.3.461.14960 |
| 35 | HERNANDEZ P, ALONSO A A, BRAVO F, et al A branch-and-cluster coordination scheme for selecting prison facility sites under uncertainty. Computers & Operations Research, 2012, 39 (9): 2232- 2241. |
| 36 | YILMAZ P, CATAY B Strategic level three-stage production distribution planning with capacity expansion. Computers & Industrial Engineering, 2006, 51 (4): 609- 620. |
| 37 | TARHAN B, GROSSMANN I E. A multistage stochastic programming approach with strategies for uncertainty reduction in the synthesis of process networks with uncertain yields. Computers & Chemical Engineering, 2008, 32(4/5): 766–788. |
| 38 |
WANG K J, WANG S M, CHEN J C A resource portfolio planning model using sampling-based stochastic programming and genetic algorithm. European Journal of Operational Research, 2008, 184 (1): 327- 340.
doi: 10.1016/j.ejor.2006.10.037 |
| 39 | AHMADIZAR F, GHAZANFARI M, GHOMI S M T F Group shops scheduling with makespan criterion subject to random release dates and processing times. Computers & Operations Research, 2010, 37 (1): 152- 162. |
| 40 |
WANG S M, WATADA J Two-stage fuzzy stochastic programming with value-at-risk criteria. Applied Soft Computing, 2011, 11 (1): 1044- 1056.
doi: 10.1016/j.asoc.2010.02.004 |
| 41 | AGHAEI J, NIKNAM T, AZIZIPANAH A R, et al Scenario-based dynamic economic emission dispatch considering load and wind power uncertainties. International Journal of Electrical Power & Energy Systems, 2013, 47 (5): 351- 367. |
| 42 |
SEKER M, NOYAN N Stochastic optimization models for the airport gate assignment problem. Transportation Research Part E: Logistics and Transportation Review, 2012, 48 (2): 438- 459.
doi: 10.1016/j.tre.2011.10.008 |
| 43 |
THANGARAJ R, PANT M, BOUVRY P, et al Solving stochastic programming problems using modified differential evolution algorithms. Logic Journal of IGPL, 2012, 20 (4): 732- 746.
doi: 10.1093/jigpal/jzr017 |
| 44 | CAO J L Algorithm research based on multi period fuzzy portfolio optimization model. Cluster Computing, 2019, 22 (2): 3445- 3452. |
| 45 |
GULTEN S, RUSZCZYNSKI A Two-stage portfolio optimization with higher-order conditional measures of risk. Annals of Operations Research, 2015, 229 (1): 409- 427.
doi: 10.1007/s10479-014-1768-2 |
| 46 | RAFIEE M, KIANFAR F. A scenario tree approach to multi-period project selection problem using real-option valuation method. The International Journal of Advanced Manufacturing Technology, 2011, 56(1/4): 411–420. |
| 47 | HOSSEINALIZADEH R, KHAMSEH A A, AKHLAGHI M M. A multi-objective and multi-period model to design a strategic development program for biodiesel fuels. Sustainable Energy Technologies and Assessments, 2019. DOI: 10.1016/j.seta.2019.100545. |
| 48 |
KHORSI M, CHAHARSOOGHI S K, BOZORGI-AMIRI A, et al A multi-objective multi-period model for humanitarian relief logistics with split delivery and multiple uses of vehicles. Journal of Systems Science and Systems Engineering, 2020, 29, 360- 378.
doi: 10.1007/s11518-019-5444-6 |
| 49 |
CHAN Y, DISALVO J P, GARRAMBONE M W A goal-seeking approach to capital budgeting. Socio-Economic Planning Sciences, 2005, 39 (2): 165- 182.
doi: 10.1016/j.seps.2004.04.002 |
| 50 | WHITACRE J M, ABBASS H A, SARKER R, et al. Strategic positioning in tactical scenario planning. Proc. of the 10th Annual Conference on Genetic and Evolutionary Computation, 2008: 1081–1088. |
| 51 |
GOLANY B, KRESS M, PENN M, et al Network optimization models for resource allocation in developing military countermeasures. Operations Research, 2012, 60 (1): 48- 63.
doi: 10.1287/opre.1110.1002 |
| 52 | XIONG J, YANG K W, LIU J, et al A two-stage preference-based evolutionary multi-objective approach for capability planning problems. Knowledge-Based Systems, 2012, 31, 128- 139. |
| 53 | XIONG J, ZHOU Z B, TIAN K, et al A multi-objective approach for weapon selection and planning problems in dynamic environments. Journal of Industrial & Management Optimization, 2017, 13 (3): 1189- 1211. |
| 54 | REMPEL M, YOUNG C A portfolio optimization model for investment planning in the department of national defence and Canadian Armed Forces. Proc. of the 46th Annual Meeting of the Decision Sciences Institute, 2015, 384- 408. |
| 55 | WANG M, ZHANG H Q, ZHANG K. A model and solving algorithm of combination planning for weapon equipment based on Epoch–era analysis method. Proc. of the AIP Conference Proceedings, 2017. DOI: 10.1063/1.5005319. |
| 56 | MOALLEMI E A, ELSAWAH S, TURAN H H, et al Multi-objective decision making in multi-period acquisition planning under deep uncertainty. Proc. of the Winter Simulation Conference, 2018, 1334- 1345. |
| 57 |
XIA B Y, ZHAO Q S, YANG K W, et al Scenario-based modeling and solving research on robust weapon project planning problems. Journal of Systems Engineering and Electronics, 2019, 30 (1): 85- 99.
doi: 10.21629/JSEE.2019.01.09 |
| 58 |
BROWN G G, DELL R F, NEWMAN A M Optimizing military capital planning. Interfaces, 2004, 34 (6): 415- 425.
doi: 10.1287/inte.1040.0107 |
| 59 |
TSAGANEA D Appropriation of funds for anti-ballistic missile defense: a dynamic model. Kybernetes, 2005, 34 (6): 824- 833.
doi: 10.1108/03684920510595517 |
| 60 | BAKER S, BENDER A, ABBASS H, et al. A scenario-based evolutionary scheduling approach for assessing future supply chain fleet capabilities. Berlin: Springer, 2007. |
| 61 | XIN B, CHEN J, PENG Z H, et al An efficient rule-based constructive heuristic to solve dynamic weapon-target assignment problem. IEEE Trans. on Systems, Man, and Cybernetics-Part A: Systems and Humans, 2010, 41 (3): 598- 606. |
| 62 |
FISHER B, BRIMBERG J, HURLEY W J An approximate dynamic programming heuristic to support non-strategic project selection for the Royal Canadian Navy. The Journal of Defense Modeling and Simulation, 2015, 12 (2): 83- 90.
doi: 10.1177/1548512913509031 |
| 63 |
FLEISCHER F M, VESTLI M, GLAERUM S Optimization model for robust acquisition decisions in the Norwegian armed forces. Interfaces, 2013, 43 (4): 352- 359.
doi: 10.1287/inte.2013.0690 |
| 64 | ZHANG P L, YANG K W, DOU Y J, et al Scenario-based approach for project portfolio selection in army engineering and manufacturing development. Journal of Systems Engineering and Electronics, 2016, 27 (1): 166- 176. |
| 65 |
SHAFI K, ELSAYED S, SARKER R, et al Scenario-based multi-period program optimization for capability-based planning using evolutionary algorithms. Applied Soft Computing, 2017, 56, 717- 729.
doi: 10.1016/j.asoc.2016.07.009 |
| 66 | FONTOURA A, HADDAD D, BEZERRA E. A deep reinforcement learning approach to asset-liability management. Proc. of the 8th Brazilian Conference on Intelligent Systems, 2019. DOI: 10.1109/BRACIS.2019.00046. |
| 67 | MAO H Z, ALIZADEH M, MENACHE I, et al. Resource management with deep reinforcement learning. Proc. of the 15th ACM Workshop on Hot Topics in Networks, 2016: 50–56. |
| 68 | MIRHOSEINI A, PHAM H, LE Q V, et al. Device placement optimization with reinforcement learning. Proc. of the 34th International Conference on Machining Learning, 2017: 2430–2439. |
| 69 | LUIS J J G, GUERSTER M, Del P I, et al. Deep reinforcement learning architecture for continuous power allocation in high throughput satellites. https://doi.org/10.48550/arXiv.1906.00571. |
| 70 | KHADILKAR H A scalable reinforcement learning algorithm for scheduling railway lines. IEEE Trans. on Intelligent Transportation Systems, 2018, 20 (2): 727- 736. |
| 71 | YANG Q Q, GAO Y Y, G Y, et al Target search path planning for naval battle field based on deep reinforcement learning. Systems Engineering and Electronics, 2022, 44 (11): 3486- 3485. |
| 72 | VINYALS O, EWALDS T, BARTUNOV S, et al. Starcraft II: a new challenge for reinforcement learning. https://doi.org/10.48550/arXiv.1708.04782. |
| 73 | HAUSKNECHT M, STONE P. Deep reinforcement learning in parameterized action space. Proc. of the International Conference on Learning Representations, 2016. DOI: 10.48550/arXiv.1511.04143. |
| 74 | LAMPLE G, CHAPLOT D S Playing FPS games with deep reinforcement learning. Proc. of the AAAI Conference on Artificial Intelligence, 2017, 2140- 2146. |
| 75 | KEMPKA M, WYDMUCH M, RUNC G, et al. Vizdoom: a doom-based AI research platform for visual reinforcement learning. Proc. of the IEEE Conference on Computational Intelligence and Games, 2016. DOI: 10.1109/CIG.2016.7860433. |
| 76 | ZHU Y K, MOTTAGHI R, KOLVE E, et al Target-driven visual navigation in indoor scenes using deep reinforcement learning. Proc. of the IEEE International Conference on Robotics and Automation, 2017, 3357- 3364. |
| 77 | GU S X, LILLICRAP T, SUTSKEVER I, et al Continuous deep Q-learning with model-based acceleration. Proc. of the International Conference on Machine Learning, 2016, 2829- 2838. |
| 78 | LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning. https://doi.org/10.48550/arXiv.1509.02971. |
| 79 | GU S X, HOLLY E, LILLICRAP T, et al Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. Proc. of the IEEE International Conference on Robotics and Automation, 2017, 3389- 3396. |
| 80 | WANG W L, CHEN H L, LI G Q, et al Deep reinforcement learning for multi-depot vehicle routing problem. Control and Decision, 2022, 37 (8): 2101- 2109. |
| 81 | KENDALL A, HAWKE J, JANZ D, et al Learning to drive in a day. Proc. of the International Conference on Robotics and Automation, 2019, 8248- 8254. |
| 82 | XIONG X, WANG J Q, ZHANG F, et al. Combining deep reinforcement learning and safety based control for autonomous driving. https://doi.org/10.48550/arXiv.1612.00147. |
| 83 | SALLAB A E L, ABDOU M, PEROT E, et al Deep reinforcement learning framework for autonomous driving. Electronic Imaging, 2017, 19, 70- 76. |
| 84 | SHARIFZADEH S, CHIOTELLIS I, TRIEBEL R, et al. Learning to drive using inverse reinforcement learning and deep Q-networks. https://doi.org/10.48550/arXiv.1612.03653. |
| 85 | TAI L, PAOLO G, LIU M Virtual-to-real deep reinforcement learning: continuous control of mobile robots for mapless navigation. Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems, 2017, 31- 36. |
| 86 | TAI L, LIU M. Towards cognitive exploration through deep reinforcement learning for mobile robots. https://doi.org/10.48550/arXiv.1610.01733. |
| 87 | ZHAO D B, ZHU Y H, LV L, et al Convolutional fitted Q iteration for vision-based control problems. Proc. of the International Joint Conference on Neural Networks, 2016, 4539- 4544. |
| 88 | HESSEL M, MODAYIL J, VAN HASSELT H, et al. Rainbow: combining improvements in deep reinforcement learning. Proc. of the AAAI Conference on Artificial Intelligence, 2018. DOI: 10.1609/aaai.v32i1.11796. |
| No related articles found! |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||