Journal of Systems Engineering and Electronics ›› 2022, Vol. 33 ›› Issue (2): 447-460.doi: 10.23919/JSEE.2022.000045
-
收稿日期:2021-08-13接受日期:2022-03-07出版日期:2022-05-06发布日期:2022-05-06
Knowledge transfer in multi-agent reinforcement learning with incremental number of agents
Wenzhang LIU1( ), Lu DONG2(), Jian LIU1(), Changyin SUN1,*()
), Lu DONG2(), Jian LIU1(), Changyin SUN1,*()
- 1 School of Automation, Southeast University, Nanjing 210096, China
2 School of Cyber Science and Engineering, Southeast University, Nanjing 211189, China
-
Received:2021-08-13Accepted:2022-03-07Online:2022-05-06Published:2022-05-06 -
Contact:Changyin SUN E-mail:wzliu@seu.edu.cn;ldong90@seu.edu.cn;bkliujian@163.com;cysun@seu.edu.cn -
About author:|LIU Wenzhang was born in 1993. He is a Ph.D. student in the School of Automation, Southeast University, Nanjing, China. He received his B.S. degree in engineering from Jilin University, Changchun, China, in 2016. He is currently working toward his Ph.D. degree in control science and engineering at Southeast University. His research interests include machine learning, deep reinforcement learning, optimal control, and multi-agent cooperative control. E-mail:
wzliu@seu.edu.cn ||DONG Lu was born in 1990. She received her B.S. degree in physics and Ph.D. degree in electrical engineering from Southeast University, Nanjing, China, in 2012 and 2017, respectively. She is currently an associate professor with the School of Cyber Science and Engineering, Southeast University. Her current research interests include adaptive dynamic programming, event-triggered control, nonlinear system control and optimization. E-mail:
ldong90@seu.edu.cn ||LIU Jian was born in 1992. He received his B.S. and Ph.D. degrees from the School of Automation and Electrical Engineering, University of Science and Technology Beijing, Beijing, China, in 2015 and 2020, respectively. From September 2017 to September 2018, he was a joint training student with the Department of Mathematics, Dartmouth College, Hanover, NH, USA. From 2020 to 2021, he was a postdoctoral fellow with the School of Automation, Southeast University, Nanjing, China, where he is currently an associate professor. His current research interests include multi-agent systems, nonlinear control, event-triggered control, and fixed-time control. E-mail:
bkliujian@163.com ||SUN Changyin was born in 1975. He received his B.S. degree in applied mathematics from the College of Mathematics, Sichuan University, Chengdu, China, in 1996, and M.S. and Ph.D. degrees in electrical engineering from Southeast University, Nanjing, China, in 2001 and 2004, respectively. He is currently a professor with the School of Automation, Southeast University, Nanjing, China. His current research interests include intelligent control, flight control, and optimal theory. He is an associate editor of the IEEE Transactions on Neural Networks and Learning Systems, Neural Processing Letters, and the IEEE/CAA Journal of Automatica Sinica. E-mail:
cysun@seu.edu.cn -
Supported by:This work was supported by the National Key R&D Program of China (2018AAA0101400), the National Natural Science Foundation of China (62173251; 61921004; U1713209), the Natural Science Foundation of Jiangsu Province of China (BK20202006), and the Guangdong Provincial Key Laboratory of Intelligent Decision and Cooperative Control.
引用本文
. [J]. Journal of Systems Engineering and Electronics, 2022, 33(2): 447-460.
Wenzhang LIU, Lu DONG, Jian LIU, Changyin SUN. Knowledge transfer in multi-agent reinforcement learning with incremental number of agents[J]. Journal of Systems Engineering and Electronics, 2022, 33(2): 447-460.
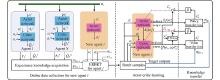
"
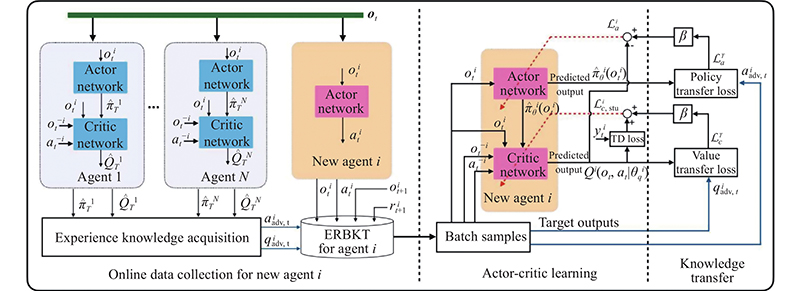
"
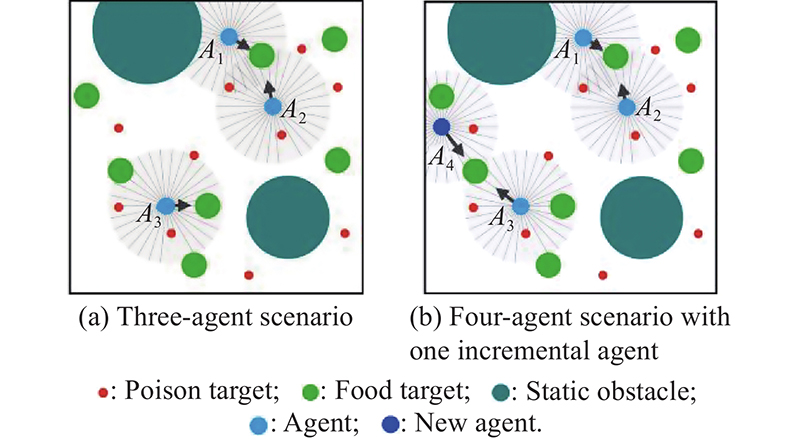
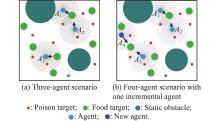
"
| Parameter | Simulation A | Simulation B |
| Discount factor γ | 0.99 | 0.99 |
| Transfer factor β | 1.0 | 20.0 |
| Learning rate critic,αc | 0.001 | 0.001 |
| Learning rate critic,αa | 0.001 | 0.001 |
| Soft update factor τ | 0.001 | 0.001 |
| Batch size Nbatch | 64 | 64 |
| Replay buffer size M | 100000 | 100000 |
| Initialize exploration variance σ | 0.2 | 0.5 |
| Hidden layer units | [100, 50, 25] | [64, 64] |
| Episode number Ne | 15000 | 24000 |
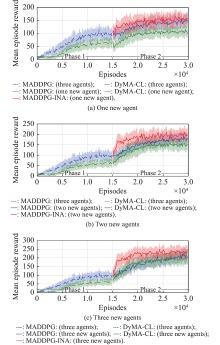
"
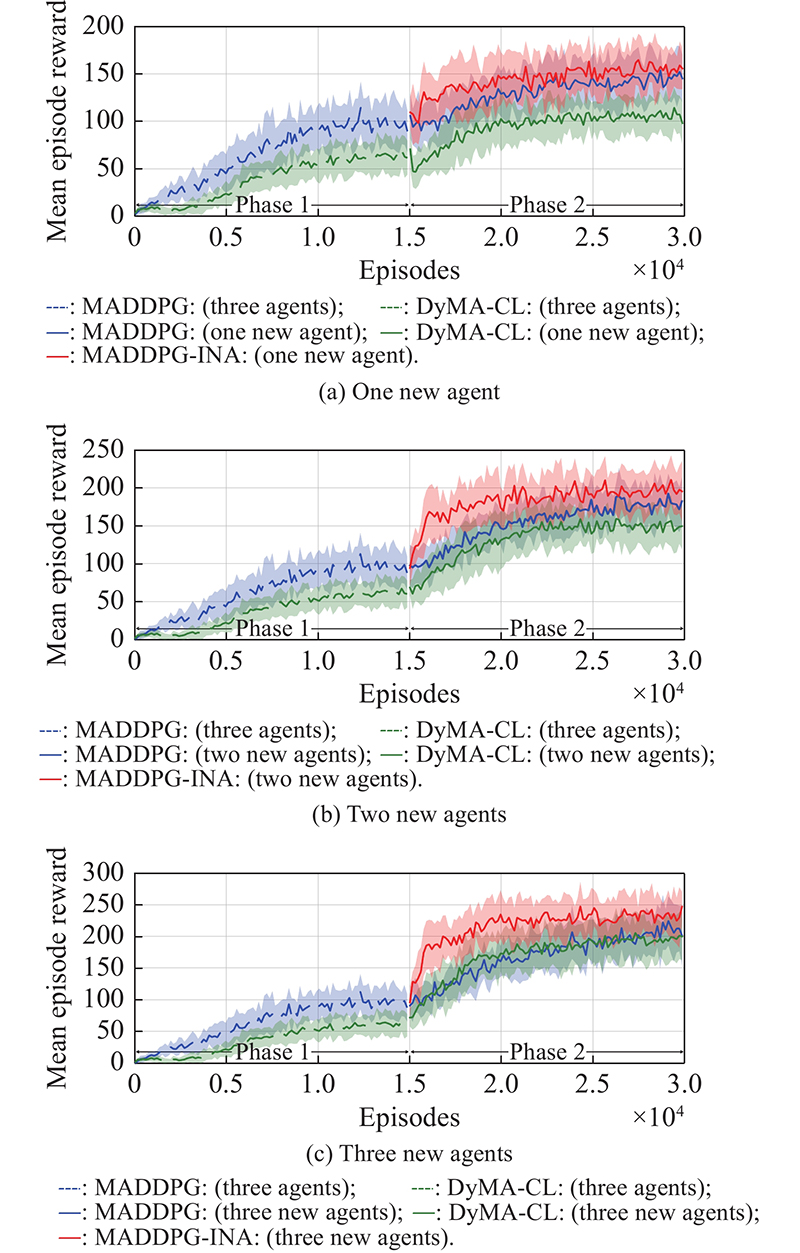
"
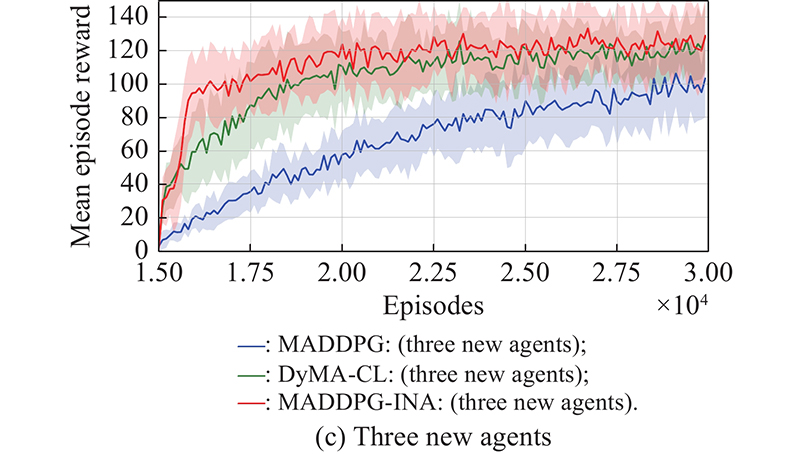
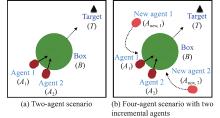
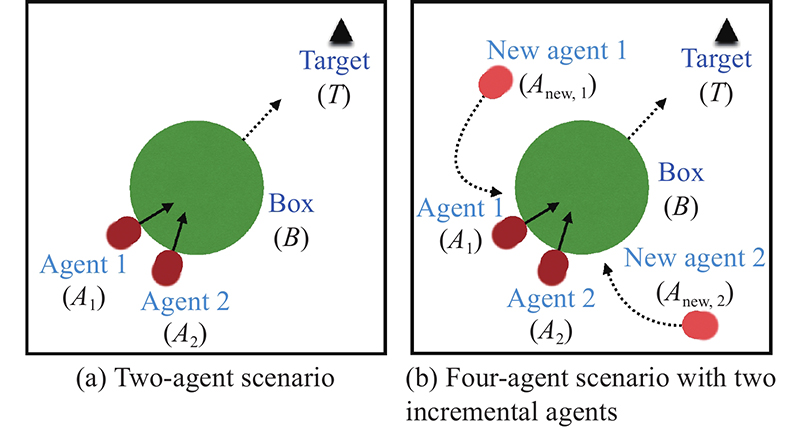
"

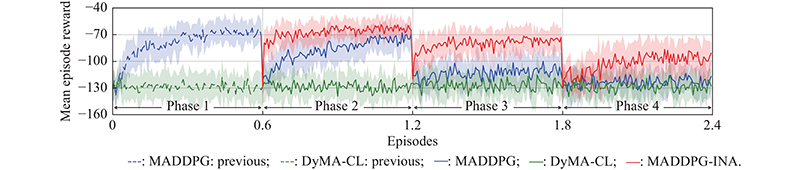
"
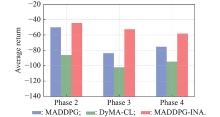
"
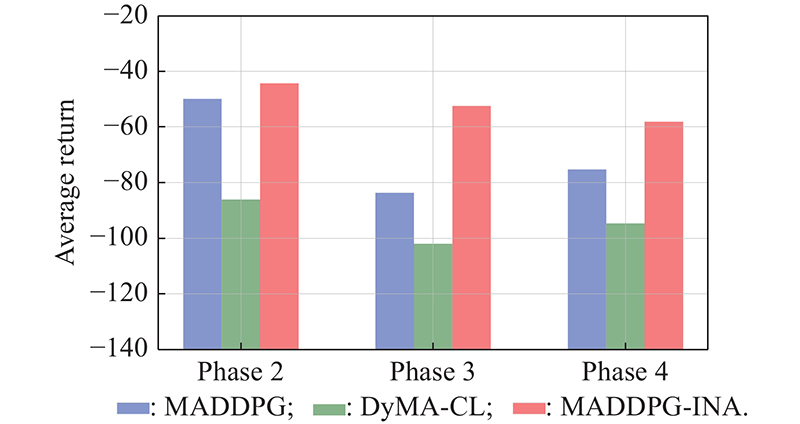
| 1 |
MNIH V, KAVUKCUOGLU K, SILVER D, et al Human-level control through deep reinforcement learning. Nature, 2015, 518 (7540): 529- 533.
doi: 10.1038/nature14236 |
| 2 | LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning. https://arxiv.org/abs/1509.02971. |
| 3 |
DONG L, YUAN X, SUN C Y Event-triggered receding horizon control via actor-critic design. Science China Information Sciences, 2020, 63 (5): 150210.
doi: 10.1007/s11432-019-2663-y |
| 4 | FUJIMOTO S, MEGER D, PRECUP D A deep reinforcement learning approach to marginalized importance sampling with the successor representation. Proc. of the 38th International Conference on Machine Learning, 2021, 3518- 3529. |
| 5 |
LI Y, QI X H, LI X D, et al Deep reinforcement learning and its application in autonomous fitting optimization for attack areas of UCAVs. Journal of Systems Engineering and Electronics, 2020, 31 (4): 734- 742.
doi: 10.23919/JSEE.2020.000048 |
| 6 |
GAO X, FANG Y W, WU Y L Fuzzy Q learning algorithm for dual-aircraft path planning to cooperatively detect targets by passive radars. Journal of Systems Engineering and Electronics, 2013, 24 (5): 800- 810.
doi: 10.1109/JSEE.2013.00093 |
| 7 |
FANG M, GROEN F C Collaborative multi-agent reinforcement learning based on experience propagation. Journal of Systems Engineering and Electronics, 2013, 24 (4): 683- 689.
doi: 10.1109/JSEE.2013.00079 |
| 8 |
TAMPUU A, MATIISEN T, KODELJA D, et al Multiagent cooperation and competition with deep reinforcement learning. PloS One, 2017, 12 (4): e0172395.
doi: 10.1371/journal.pone.0172395 |
| 9 |
NGUYEN T T, NGUYEN N D, NAHAVANDI S Deep reinforcement learning for multiagent systems: a review of challenges, solutions, and applications. IEEE Trans. on Cybernetics, 2020, 50 (9): 3826- 3839.
doi: 10.1109/TCYB.2020.2977374 |
| 10 | LOWE R, WU Y, TAMAR A, et al Multi-agent actor-critic for mixed cooperative-competitive environments. Proc. of the Annual Conference on Neural Information Processing Systems, 2017, 6379- 6390. |
| 11 | FOERSTER J, FARQUHAR G, AFOURAS T, et al Counterfactual multi-agent policy gradients. Proc. of the AAAI Conference on Artificial Intelligence, 2018, 2974- 2982. |
| 12 | SUNEHAG P, LEVER G, GRUSLYS A, et al Value-decomposition networks for cooperative multi-agent learning based on team reward. Proc. of the 17th International Conference on Autonomous Agents and MultiAgent Systems, 2018, 2085- 2087. |
| 13 | RASHID T, SAMVELYAN M, SCHRODER D W, et al Qmix: monotonic value function factorisation for deep multi-agent reinforcement learning. Proc. of the 35th International Conference on Machine Learning, 2018, 4292- 4301. |
| 14 |
PAN S J, YANG Q A survey on transfer learning. IEEE Trans. on Knowledge and Data Engineering, 2010, 22 (10): 1345- 1359.
doi: 10.1109/TKDE.2009.191 |
| 15 | LONG M S, ZHU H, WANG J M, et al Deep transfer learning with joint adaptation networks. Proc. of the 34th International Conference on Machine Learning, 2017, 2208- 2217. |
| 16 |
ZHUANG F Z, QI Z Y, DUAN K Y, et al A comprehensive survey on transfer learning. Proceedings of the IEEE, 2021, 109 (1): 43- 76.
doi: 10.1109/JPROC.2020.3004555 |
| 17 | TAYLOR M E, STONE P Transfer learning for reinforcement learning domains: a survey. Journal of Machine Learning Research, 2009, 10 (7): 1633- 1685. |
| 18 | LAZARIC A Transfer in reinforcement learning: a framework and a survey. Proc. of the Reinforcement Learning, 2012, 143- 173. |
| 19 | ZHU Z D, LIN K X, ZHOU J Y. Transfer learning in deep reinforcement learning: a survey. https://arxiv.org/abs/2009.07888. |
| 20 | TAYLOR M E, STONE P Behavior transfer for value-function-based reinforcement learning. Proc. of the 4th International Joint Conference on Autonomous Agents and Multiagent Systems, 2005, 53- 59. |
| 21 | BOUTSIOUKIS G, PARTALAS I, VLAHAVAS I Transfer learning in multi-agent reinforcement learning domains. Proc. of the European Workshop on Reinforcement Learning, 2011, 249- 260. |
| 22 |
SILVA F L D, COSTA A H R A survey on transfer learning for multiagent reinforcement learning systems. Journal of Artificial Intelligence Research, 2019, 64, 645- 703.
doi: 10.1613/jair.1.11396 |
| 23 | SILVA F L D, WARNELL G, COSTA A H R, et al Agents teaching agents: a survey on inter-agent transfer learning. Proc. of the 19th International Conference on Autonomous Agents and Multiagent Systems, 2020, 2165- 2167. |
| 24 | WADHWANIA S, KIM D K, OMIDSHAFIEI S, et al Policy distillation and value matching in multiagent reinforcement learning. Proc. of the IEEE/RSJ International Conference on Intelligent Robots and Systems, 2019, 8193- 8200. |
| 25 | YANG T P, WANG W X, TANG H Y, et al. Transfer among agents: an efficient multiagent transfer learning framework. https://arxiv.org/abs/2002.08030. |
| 26 | RUSU A A, COLMENAREJO S G, GULCEHRE C, et al. Policy distillation. http://arxiv.org/abs/1511.06295. |
| 27 | PARISOTTO E, BA J L, SALAKHUTDINOV R. Actor-mimic: deep multitask and transfer reinforcement learning. http://arxiv.org/abs/1511.06342. |
| 28 | OMIDSHAFIEI S, PAZIS J, AMATO C, et al Deep decentralized multi-task multi-agent reinforcement learning under partial observability. Proc. of the 34th International Conference on Machine Learning, 2017, 2681- 2690. |
| 29 |
LI Z, BARENJI A V, JIANG J Z, et al A mechanism for scheduling multi robot intelligent warehouse system face with dynamic demand. Journal of Intelligent Manufacturing, 2020, 31 (2): 469- 480.
doi: 10.1007/s10845-018-1459-y |
| 30 | WANG W X, YANG T P, LIU Y, et al From few to more: large-scale dynamic multiagent curriculum learning. Proc. of the AAAI Conference on Artificial Intelligence, 2020, 7293- 7300. |
| 31 | CHEN D, LI Z J, WANG Y Q, et al. Deep multi-agent reinforcement learning for highway on-ramp merging in mixed traffic. https://arxiv.org/abs/2105.05701. |
| 32 | CZARNECKI W M, PASCANU R, OSINDERO S, et al Distilling policy distillation. Proc. of the 22th International Conference on Artificial Intelligence and Statistics, 2019, 1331- 1340. |
| 33 | CHEN G A new framework for multi-agent reinforcement learning−centralized training and exploration with decentralized execution via policy distillation. Proc. of the 19th International Conference on Autonomous Agents and Multiagent Systems, 2020, 1801- 1803. |
| 34 | TAYLOR A, DUSPARIC I, GUÉRIAU M, et al. Parallel transfer learning in multi-agent systems: what, when and how to transfer. Proc. of the International Joint Conference on Neural Networks, 2019. DOI: 10.1109/IJCNN.2019.8851784. |
| 35 | AGARWAL A, KUMAR S, SYCARA K P, et al Learning transferable cooperative behavior in multi-agent teams. Proc. of the 19th International Conference on Autonomous Agents and Multiagent Systems, 2020, 1741- 1743. |
| 36 | SUTTON R S, BARTO A G. Reinforcement learning: an introduction. Cambridge: The MIT Press, 2018. |
| 37 | BELLMAN R, KALABA RE. Dynamic programming and modern control theory. New York: Academic Press, 1965. |
| 38 | ZHAO P L, HOI S C OTL: a framework of online transfer learning. Proc. of the 27th International Conference on Machine Learning, 2010, 1231- 1238. |
| 39 | LI Y Y, ZHOU W, WANG H M, et al. Improving fast adaptation for newcomers in multi-robot reinforcement learning system. Proc. of the IEEE Smart World, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation, 2019: 753-760. |
| 40 | GUPTA J K, EGOROV M, KOCHENDERFER M Cooperative multi-agent control using deep reinforcement learning. Proc. of the International Conference on Autonomous Agents and Multiagent Systems, 2017, 66- 83. |
| 41 | NAIR V, HINTON G E Rectified linear units improve restricted boltzmann machines. Proc. of the 27th International Conference on Machine Learning, 2010, 807- 814. |
| No related articles found! |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||