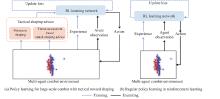
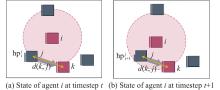
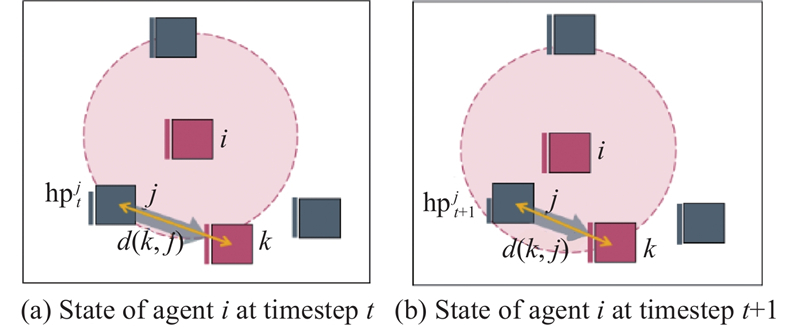
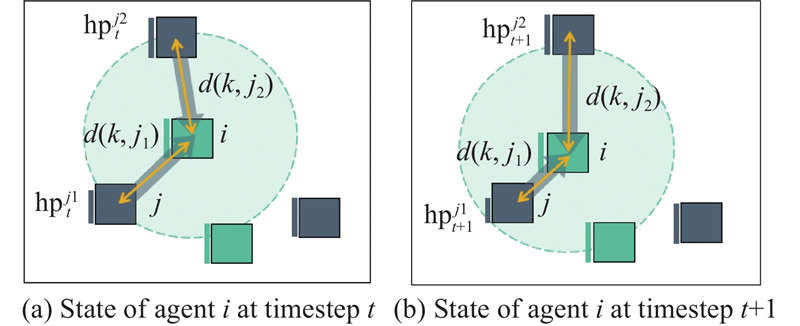
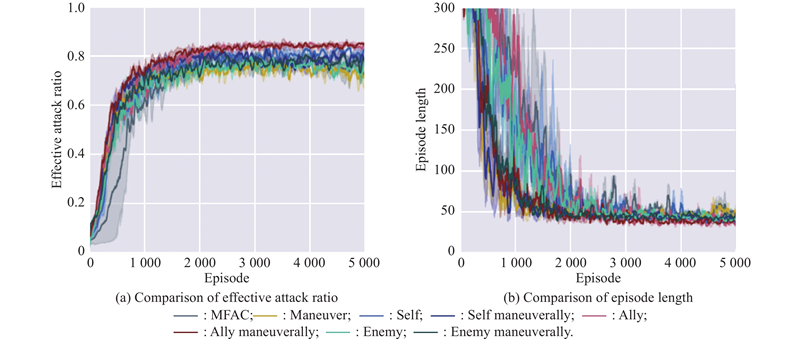
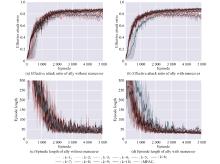
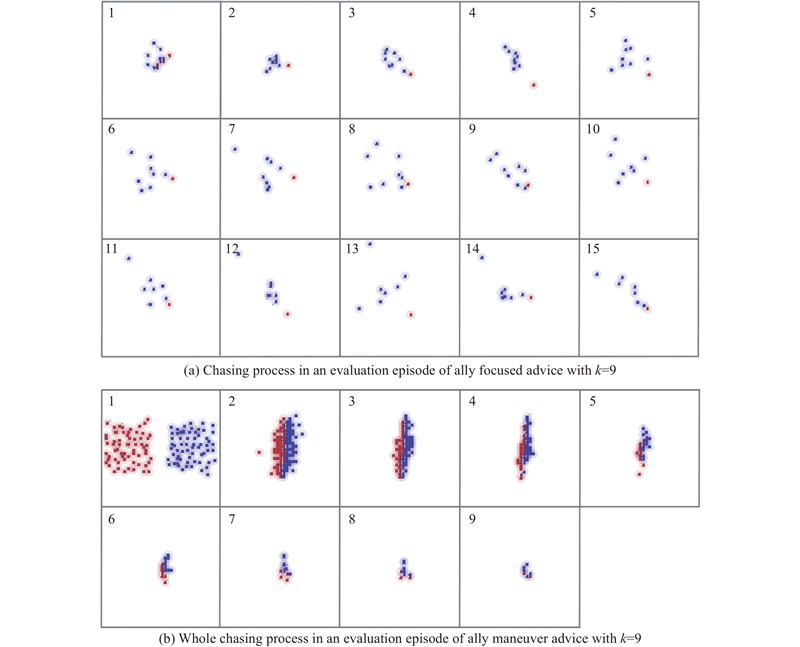
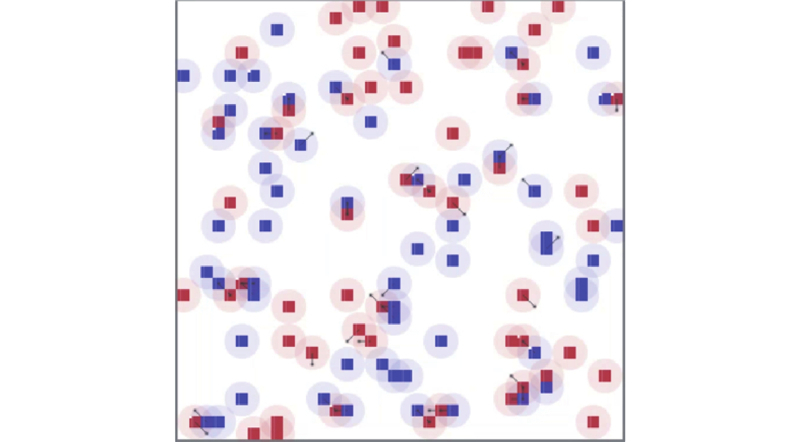
| 1 |
CIL I, MALA M A multi-agent architecture for modelling and simulation of small military unit combat in asymmetric warfare. Expert Systems with Applications, 2010, 37 (2): 1331- 1343.
doi: 10.1016/j.eswa.2009.06.024
|
| 2 |
BUSONIU L, BABUSKA R, DE SCHUTTER B A comprehensive survey of multiagent reinforcement learning. IEEE Trans on Systems, Man, and Cybernetics−Part C: Applications and Reviews, 2008, 38, 156- 172.
|
| 3 |
LIU L B, LUO C M, SHEN F R. Multi-agent formation control with target tracking and navigation. Proc. of the IEEE International Conference on Information and Automation, 2017: 98−103.
|
| 4 |
WEN G X, CHEN C P, FENG J, et al Optimized multi-agent formation control based on an identifier-actor-critic reinforcement learning algorithm. IEEE Trans. on Fuzzy Systems, 2017, 26, 2719- 2731.
|
| 5 |
YANG J C, ZHANG J P, WANG H H. Urban traffic control in software defined internet of things via a multi-agent deep reinforcement learning approach. IEEE Trans. on Intelligent Transportation Systems, 2020, 22: 3742–3754.
|
| 6 |
WIERING M A. Multi-agent reinforcement learning for traffic light control. Proc. of the 17th International Conferenconeon Machine Learning, 2000: 1151−1158.
|
| 7 |
VINYALS O, BABUSCHKIN I, CZARNECKI W M, et al Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 2019, 575 (7782): 350- 354.
doi: 10.1038/s41586-019-1724-z
|
| 8 |
CHANG Y H, HO T, KAELBLING L. All learning is local: multi-agent learning in global reward games. Proc. of the Advances in Neural Information Processing Systems, 2003: 16.
|
| 9 |
AGOGINO A K, TUMER K Analyzing and visualizing multiagent rewards in dynamic and stochastic domains. Autonomous Agents and Multi-Agent Systems, 2008, 17, 320- 338.
doi: 10.1007/s10458-008-9046-9
|
| 10 |
DEVLIN S, KUDENKO D, GRZES M An empirical study of potential-based reward shaping and advice in complex, multi-agent systems. Advances in Complex Systems, 2011, 14 (2): 251- 278.
doi: 10.1142/S0219525911002998
|
| 11 |
DEVLIN S, YLINIEMI L, KUDENKO D, et al. Potential-based difference rewards for multiagent reinforcement learning. Proc. of the International Conference on Autonomous Agents and Multi-Agent Systems, 2014: 165−172.
|
| 12 |
LOWE R, WU Y I, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments. Proc. of the 31st International Conference on Neural Information Processing Systems, 2017, 30: 6382−6393.
|
| 13 |
FOERSTER J, FARQUHAR G, AFOURAS T, et al. Counterfactual multi-agent policy gradients. Proc. of the 32nd AAAI Conference on Artificial Intelligence, 2018. https://doi.org/10.1609/aaai.v32il.11794.
|
| 14 |
LI J H, KUANG K, WANG B X, et al. Shapley counterfactual credits for multi-agent reinforcement learning. Proc. of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, 2021: 934−942.
|
| 15 |
SHAPLEY L S. A value for n-person games. WILLIAM K H, ed. Classics in game theory. Princeton: Princeton University Press, 1997.
|
| 16 |
SUNEHAG P, LEVER G, GRUSLYS A, et al. Value-decomposition networks for cooperative multi-agent learning. https://arxiv.org/abs/1706.05296.
|
| 17 |
RASHID T, SAMVELYAN M, DE WITT C S, et al Monotonic value function factorisation for deep multi-agent reinforcement learning. The Journal of Machine Learning Research, 2020, 21 (1): 7234- 7284.
|
| 18 |
NG A Y, HARADA D, RUSSELL S. Policy invariance under reward transformations: theory and application to reward shaping. Proc. of the International Conference on Machine Learning, 1999: 278−287.
|
| 19 |
BRYS T, HARUTYUNYAN A, SUAY H B, et al. Reinforcement learning from demonstration through shaping. Proc. of the 24th International Joint Conference on Artificial Intelligence, 2015: 3352−3358.
|
| 20 |
BADNAVA B, MOZAYANI N. A new potential-based reward shaping for reinforcement learning agent. Proc. of the 13th Annual Computing and Communication Workshop and Conference, 2023. DOI: 10.1109/CCWC57344.2023.10099211.
|
| 21 |
WANG Z, LI H, WU H L, et al. Improving maneuver strategy in air combat by alternate freeze games with a deep reinforcement learning algorithm. Mathematical Problems in Engineering, 2020, 2020: 7180639.
|
| 22 |
SAMVELYAN M, RASHID T, DE WITT C S, et al. The starcraft multi-agent challenge. https://arxiv.org/abs/1902.04043.
|
| 23 |
HUANG L W, FU M S, QU H, et al A deep reinforcement learning-based method applied for solving multi-agent defense and attack problems. Expert Systems with Applications, 2021, 176, 114896.
doi: 10.1016/j.eswa.2021.114896
|
| 24 |
BROCKMAN G, CHEUNG V, PETTERSSON L, et al. Openai gym. https://arxiv.org/abs/1606.01540.
|
| 25 |
ZAMORA I, LOPEZ N G, VILCHES V M, et al. Extending the openai gym for robotics: a toolkit for reinforcement learning using ros and gazebo. https://arxiv.org/abs/1608.05742.
|
| 26 |
MORDATCH I, ABBEEL P. Emergence of grounded compositional language in multi-agent populations. Proc. of the 32nd AAAI Conference on Artificial Intelligence, 2018. DOI: https://doi.org/10.1609/aaai.v32i1.11492.
|
| 27 |
LIU I J, JAIN U, YEH R A, et al. Cooperative exploration for multi-agent deep reinforcement learning. Proc. of the International Conference on Machine Learning, 2021: 6826−6836.
|
| 28 |
ZHENG L M, YANG J C, CAI H, et al. Magent: a many-agent reinforcement learning platform for artificial collective intelligence. Proc. of the 32nd AAAI Conference on Artificial Intelligence, 2018. DOI: https://doi.org/10.1609/aaai.v32i1.11371.
|
| 29 |
YANG Y D, LUO R, LI M, et al. Mean field multi-agent reinforcement learning. Proc. of the International Conference on Machine Learning, 2018: 5571−5580.
|
| 30 |
DEVLIN S, KUDENKO D. Theoretical considerations of potential-based reward shaping for multi-agent systems. Proc. of the 10th International Conference on Autonomous Agents and Multiagent Systems, 2011: 225−232.
|
| 31 |
ASMUTH J, LITTMAN M L, ZINKOV R. Potential-based shaping in model-based reinforcement learning. Proc. of the AAAI Conference on Artificial Intelligence, 2008: 604–609.
|
 ), Qinzhao WANG1(
), Qinzhao WANG1(